14-05-2014 23:06
Historia sobre os sites de busca
A Historia dos sites de busca começou em 1945 com As We May Think:
O ensaio As We May Think (Como nós podemos pensar) de Vannevar Bush, foi primeiro publicado em The Atlantic Monthly em julho de 1945, argumentava que enquanto os humanos viravão as costas para a guerra, esforços científicos deveriam variar do aumento de habilidades físicas para fazer com que todo o conhecimento humano fosse previamente coletado e fosse mais acessível para todos. O conceito de hipertexto uma extensão de memória veio realmente a vida em Julho de 1945 publicado no The Atlantic Monthly.
A historia dos sites de busca na Internet começou em 1945 e é hoje facilitada através da utilização de sites de busca e sites de pesquisa. A historia dos sites de busca, sites de pesquisa na internet era através de sites já conhecidos, na esperança de encontrar um link útil que leve a outro site. Abaixo está uma boa leitura que mostra um resumo da história dos sites de busca. Este site é atualizado conforme os acontecimentos históricos dos sites de busca e sobre a história, dos sites de busca e sites de pesquisa, historia dos sites de relacionamento e tudo sobre sites de busca. Este site é um excelente recurso para uma pesquisa da história dos sites de busca.
A rede mundial de computadores, ou também a Internet, surgiu em plena Guerra Fria. Criada para objetivos militares, seria uma das formas mais avançada das forças armadas norte-americanas de manter as comunicações em caso de ataques inimigos que destruíssem os meios de telecomunicações convencionais. Nas décadas de 1970 e 1980, além de ser utilizada para fins militares, a Internet também foi um importante meio de comunicação acadêmico. Estudantes e professores universitários, principalmente dos EUA, trocavam idéias, mensagens e descobertas pelas linhas da rede mundial criando por exemplo o Archie.
Vannevar Bush:

Vannevar Bush nasceu a 11 de Março de 1890 em Chelsea, Massachusetts. Foi uma criança predisposta a adoecer o que o forçou a estar acamado frequentemente. Isto não lhe retirou a confiança, diz-se que era usual envolver-se em cenas de pancadaria com os outras crianças. Engenheiro elétrico, físico, inventor e político, nascido em Everett, Massachusetts, conhecido pelo seu papel político no desenvolvimento da bomba atômica e pela idéia do site de busca memex (1945), visto como um conceito pioneiro, precursor da world wide web.Filho de um ministro universalista, foi um bom aluno na escola, revelando especial aptidão na matemática. Quando terminou o liceu ingressou no Tufts College para estudar engenharia. Neste período produziu a sua primeira invenção, um aparelho para registro de relevo ao qual chamou de profile tracer.Foi essa tecnologia básica que se tornou o ponto de partida para muitas das máquinas analógicas que Vannevar Bush desenvolveu mais tarde no MIT com seus alunos de pós-graduação. Após se ter licenciado na Tufts foi trabalhar para a General Electrics onde testava equipamentos eléctricos, de onde saiu (1914). Despediram-no depois de um fogo acidental na sua fábrica. Em 1914 arranjou emprego como professor de matemática na Clark University em Massachussetts. No ano seguinte decidiu regressar aos estudos. Ofereceram-lhe uma bolsa de 1500 dólares para realizar o seu doutoramento sob a orientação de um professor chamado Arthur Webster. Webster queria que Bush dedicasse o seu estudo ao campo da acústica, mas Vannevar Bush, não gostava que lhe dissessem o que devia fazer recusou a bolsa. Em vez de permanecer ali fez o doutoramento no MIT em menos de um ano e regressou a Tufts como professor assistente. Idealizou um aparelho que usaria campos magnéticos para detectar os submarinos e viajou para Washington (1917) para pedir apoio a National Research Council, a NRC, e obteve sucesso em sua empreitada. Deixou Tufts definitivamente e ingressou no departamento de engenharia elétrica do Massachusetts Institute of Technology (1919-1938), onde projetou em 1928 uma máquina de análise diferencial, um precursor do computador, além de dirigir a equipe que produziu a primeira bomba atômica como diretor do Office of Scientific Research and Development. Presidente da Carnegie Institution (1938-1955), publicou vários livros e artigos destacando o Modern Arms and Free Men (1949) e morreu de pneumonia após sofrer um derrame, em Belmont, Massachusetts.

Em 1940, Vannevar Bush e outros engenheiros sentiram que o país necessitava de uma nova organização para conduzir a investigação científica. Cientistas, governo, militares bem como iniciativa privada necessitavam de cooperar entre si para os Estados Unidos estarem preparados na eventualidade de uma guerra.
Em 12 de Junho de 1940 Vannevar Bush encontrou-se com o Presidente Roosevelt e expôs detalhadamente o seu plano para mobilizar a pesquisa científica no campo militar. Sugeriu a criação de uma nova organização chamada National Defense Research Comitee (NDRC), que uniria no mesmo esforço o governo, os militares e os cientistas. Roosevelt concordou imediatamente e assim criou-se o que fora proposto. Bush era o presidente e tinha mesmo uma linha directa para a Casa Branca. Em meados de 1941 criou-se o "Office of Scientific Research and Development". O NDRC foi financiado por fundos presidenciais de emergência e estava frequentemente com falta de dinheiro. O OSRD era financiado pelo Congresso. Vannevar Bush tornou-se director do OSRD.
O NDRC e o OSRD foram originalmente montados para suportarem e aumentarem a pesquisa da marinha e do exército, mas no final da guerra era o OSRD que liderava a pesquisa científica. Muitas inovações resultaram da pesquisa da OSRD incluindo-se melhoramentos no radar, tácticas anti-submarino, e variados aparelhos secretos para o OSS - o percursor da CIA. Vannevar Bush estava também envolvido intimamente com o Projecto Manhattan, do qual saiu a primeira bomba nuclear. Claro que todo este trabalho era altamente secreto mas Bush acabou mesmo por ser uma celebridade. Uma revista disse que este era o homem que poderia ganhar ou perder a guerra.
O trabalho de Bush com a NDRC e o OSRD ajudaram de fato os EUA e os seus aliados a ganharem a guerra. Vannevar Bush modificou também a maneira como a pesquisa cientifica era conduzida nos EUA. Provou que a tecnologia era a chave para a vitória numa guerra e isto criou uma aura de respeito em torno dos cientistas. Institucionalizou a relação entre o governo, o setor privado e a comunidade científica. Bush tornou-se um dos responsáveis desta máquina, e foi esta máquina, este apoio governamental, que mais tarde alimentou o nascimento da Internet.
Fim da Guerra
No final de 1944 a vitória aliada adivinhava-se como algo de inevitável. Bush tinha agora tempo, acreditava na necessidade de apoio permanente à ciência. Em Março de 1945 Bush escreveu um artigo intitulado, "Science - The Endless Frontier". Falava sobre a necessidade de uma politica que apoiasse continuadamente a pesquisa científica e a educação, que apoiasse organizações sem fins lucrativos que procurassem desenvolver projectos científicos, que alicerçasse o nascimento de novos talentos na área através dos meios académicos e de mecenato. Isto nunca se concretizou na realidade, mas metade poder-se-á dizer que foi alcançado. A "National Science Foundation" foi criada, mas não correspondeu às expectativas de Vannevar Bush, mesmo assim o casamento entre a ciência e o governo foi institucionalizado!
Dr. Vannevar Bush foi um dos engenheiros mais avançados de sua época, graduou-se em Tufts College e estudou no MIT, onde ele se aventurou na área da computação ajudando a criar na Primeira Guerra Mundial o desenvolvimento de detecção de submarinos e agentes químicos. Suas invenções revolucionaram a area Computacional, graças ao analisador diferencial. Dr. Vannevar Bush permitiu um avanço na otimização de processos de software.
Sua contribuição para a história da Internet e a historia dos sites de busca foi a criação do que seria o início do hipertexto através do dispositivo Memex. A operação deste dispositivo foi com base nos processos da mente humana, que se distinguem pelas associações entre ações e objetos, bem como, a escolha entre um objeto e outro que seria feito mediante a indexação.
Vannevar Bush propôs a construção de um dispositivo de uso pessoal, denominado Memex, que permitiria o armazenamento de conteúdos em microfilmes e uma forma alternativa de indexação através da criação de associações entre conteúdos relacionados.
As principais características do Memex foram mapeadas para tecnologias disponíveis atualmente e algumas de suas funcionalidades foram estendidas no sistema Yai, projetado para apoiar professores de escolas públicas.
Este artigo descreve, em particular, a construção das chamadas trilhas no Yai, apresentando conceitos nela utilizados e sua relação com a construção coletiva de conhecimento.
Trilhas no Ya
Na proposta original, o Memex de Vannevar Bush seria um conjunto de dispositivos eletromecânicos dispostos em uma mesa com gavetas para o armazenamento de microfilmes. Através de um conjunto de teclas e botões, o usuário poderia solicitar, ao informar códigos, a apresentação de conteúdos em duas telas existentes sobre a mesa. Os conteúdos visualizados poderiam receber marcações especiais para, assim, estabelecer uma associação entre eles em caráter permanente. Tais associações seriam armazenadas junto aos registros destes conteúdos nos microfilmes. Uma sucessão de uma ou mais associações era denominada trilha e trilhas poderiam ser utilizadas pelo usuário no processo de recuperação da informação em momentos posteriores.Então, no Memex, os conteúdos poderiam ser encontrados de duas formas: através de um código de identificação (índice convencional) ou através da navegação em trilhas, refazendo trajetórias anteriormente percorridas e marcadas.
Entre as diversas opções oferecidas pelo Memex foi armazenar os arquivos de referência rápida, permitindo aos usuários criar links para artigos de interesse e alterar as configurações em seu banco de dados.
Como Diretor do Instituto de investigação científica e desenvolvimento, Dr. Vannevar Bush tinha coordenado a atividade de cerca de seis mil cientistas americanos na aplicação da ciência à guerra. No final da 2ª Guerra Mundial, o governo norte-americano solicitou ao cientista um estudo com o objetivo de sugerir alguns novos rumos que poderiam ser seguidos por atividades de pesquisa, até então voltadas para questões bélicas.
Em um artigo significativo Dr. Vannevar Bush acomoda até um incentivo para os cientistas deixarem de pensar em tecnologia voltada para a guerra. Ele insiste que homens da ciência, devem trabalhar na enorme tarefa de tornar mais acessível nosso desconcertante conhecimento.Sites de busca são novos resultados, mas não os resultados finais da ciência moderna, afirma Dr. Bush, são instrumentos em mãos que, se adequadamente desenvolvido, dará ao Homem acesso ilimitado sobre o conhecimento herdado em logos anos da humanidade. A perfeição destes instrumentos pacíficos deve ser o primeiro objetivo de nossos cientistas.

O primeiro (relativamente) computador analógico em grande escala foi o "analisador diferencial 'inventado e construído por Vannevar Bush (1980-1974) no início da década de 1930. A máquina era uma montagem completamente mecânica de engrenagens e eixos movidos por motores elétricos. A foto ao lado mostra Bush e seu analisador diferencial em um laboratório E.U. Exército durante a Segunda Guerra Mundial.
Veja a foto do dispositivo Memex
O aparelho seria uma mesa de trabalho , com telas para projeção, teclado e botões e alavancas: o conteúdo armazenado seria armazenado em microfilme em um canto da mesa.

Seu famoso artigo As we may think se tornou referência obrigatória, por seu entendimento da apropriação dos avanços tecnológicos no processo de acesso e recuperação da informação, mediante concepção do dispositivo memex. “Memex é um dispositivo no qual o indivíduo armazena seus livros, registros e comunicações, o qual é mecanizado, podendo ser consultado com extrema velocidade e flexibilidade. É um suplemento ampliado e próximo de sua memória.
"As We May Think"consubstanciava-se neste artigo uma ideia amadurecida durante muitos anos em pedaços esparsos de papel. O seu objectivo ao publicar era o de influenciar o pensamento, no que concerne à ciência, do mundo moderno e enfatizar a oportunidade para a aplicação da ciência num campo negligenciado. Este campo era o da automação ou exponenciação do pensamento humano!
Aqui estão algumas frases selecionadas e parágrafos que demonstrarão seu ponto de vista:
A especialização se torna cada vez mais necessária para o progresso e o esforço da humanidade. A dificuldade aparece, não tanto que encontremos a solução, não atendendo somente aos interesses do dia de hoje, mas sim que publiquemos muito além da nossa presente capacidade de fazer uso real do registro. A soma da experiência humana está se expandindo a uma taxa enorme, e os meios que utilizamos para atravessar esse labirinto são os mesmos meios que eram usado na época dos navios square-rigged. Um registro para ser útil a ciência deve ser continuamente expandida deve ser armazenada e acima de tudo deve ser consultada.
Vannevar Bush não só acredita no armazenamento de dados, acreditava tambem que se a fonte de dados era ou foi útil para a mente humana tinha que ser armazenada para se entender melhor como a mente humana funciona. Nossa incapacidade de obter o registro armazenado é em grande parte causada por problemas de indexação. Para encontrar um link util, era necessário sair do sistema e procurar novamente em uma nova indexação. A mente humana não funciona desta maneira. Ela opera por associação. ... O Homem não pode esperar que esse processo de indexação seja feito todo artificialmente por um site de busca , mas certamente o site de busca deveria ser capaz de entender a mente humana.
De forma que ele possa até mesmo ser melhorado. O conhecimento do Homem pode ser elevado se ele poder revisar seu próprio passado analisar mais completamente os seus erros e objectivamente seus problemas presentes. O homem tem construído uma civilização tão complexa que ele precisa guardar suas escritas e conhecimento para sua conclusão lógica e não meramente tornar-se inadaptada por sobrecarregar sua memória limitada. Ele então propôs a idéia de um sistema de recuperação e armazenamento de memória praticamente ilimitado, rápido, confiável, extensível e associativo. Nomeando este dispositivo com o nome de memex.
A tentativa de fazer uma máquina que organizasse a informação de modo similar à memória humana, transcende o campo da simples tecnologia. Aqui entramos no mundo do pensamento e da maneira como, para Bush, o cérebro humano devolve a informação: por associação de ideias e não por ordem alfabética ou numérica. Deste modo, surgi a ideia de uma máquina chamada “as we may think”
A idéia inovadora de Bush para automatizar a memória humana era obviamente importante para o desenvolvimento era digital, mas ainda mais importante foi sua influência sobre a instituição da ciência na América. Seu trabalho para criar uma relação entre o governo e a comunidade científica durante a Segunda Guerra mundial mudou a forma como a investigação científica é realizada nos E.U.A e fomentou o ambiente no qual a Internet foi criada mais tarde.
GERARD SALTON:
 Gerard Salton,morreu em 28 de Agosto de 1995, foi o pai da tecnologia de pesquisa moderna. Suas equipes em Harvard e Cornell desenvolveram o sistema de recuperação de informativo SMART. Magic automáticas recuperador de texto da Salton incluído conceitos importantes como o modelo de espaço de vetor, freqüência de documento inverso (IDF), termo freqüência (TF), valores de discriminação de prazo e mecanismos de feedback de rel evância. Ele é autor de um livro de 56 página chamado A teoria de indexação que faz um ótimo trabalho explicando muitos de seus testes de pesquisa continua .
Gerard Salton,morreu em 28 de Agosto de 1995, foi o pai da tecnologia de pesquisa moderna. Suas equipes em Harvard e Cornell desenvolveram o sistema de recuperação de informativo SMART. Magic automáticas recuperador de texto da Salton incluído conceitos importantes como o modelo de espaço de vetor, freqüência de documento inverso (IDF), termo freqüência (TF), valores de discriminação de prazo e mecanismos de feedback de rel evância. Ele é autor de um livro de 56 página chamado A teoria de indexação que faz um ótimo trabalho explicando muitos de seus testes de pesquisa continua .
Segundo Gerard Salton, relevância é a correspondência contextual entre uma consulta e uma informação, ou seja, a relevância indica o quanto a informação é apropriada para o solicitante, ou o quanto é importante para o usuário determinada informação.Fica claro que a relevância é, em parte, determinada em função de como o usuário formulou sua consulta. Os sistemas de recuperação de informações, numa primeira fase (primeira geração),utilizavam-se basicamente de um conjunto de fichas em que era possível recuperar informações fornecendo como entrada alguns tipos de dados, como por exemplo, o título do documento ou onome do autor. Posteriormente, avanços nos modos de busca foram sendo acrescentados, permitindo também pesquisar por assuntos ou palavras-chave e elaborar consultas mais complexas. Atualmente pode-se contar com o auxílio de interfaces gráficas , formulários eletrônicos e hipertextos na formulação das consultas. Entretanto, muitos dos mecanismos de busca hoje existentes continuam usando índices muito similares aos que eram utilizadas por bibliotecas há mais de um século .
TED NELSON:

Este homem tem sido um dos maiores avanços tecnológicos, pioneiro em ser um filósofo e sociólogo, permitindo-lhe ver de uma forma mais sintetizada em que hoje seria a maneira pela qual concebemos a informação na web. Entre os seus grandes prêmios e ovações de pé é o título de cavaleiro concedido na França e reconhecimento como um professor honorário da Universidade de Oxford, onde ele está atualmente à frente de suas pesquisas.
Sua grande contribuição para a história da Internet começa com o projeto Xanadu que expressa a possibilidade de implementar uma gestão de natureza de texto eletrônico, além de complementá-lo com uma não-escrita sequencial, mas sim com base em índices. Embora use muitas bases de estudo do Vannevar Bush, a grande diferença entre a contribuição desses dois, é que o primeiro imaginou um sistema de arquivos para prestação de serviço universal, que iria integrar servidores remotos com grande capacidade de armazenamento e processamento de informações, enquanto Ted Nelson tinha uma noção mais individualista do projeto.
O conceito de "linkar" ou de "ligar" textos foi criado por Ted Nelson. Ted Nelson criou o Projeto Xanadu, em 1960, e escreveu o termo hipertexto em 1963. Seu objetivo com o Projeto Xanadu foi criar uma rede de computadores com uma interface simples que resolveu muitos problemas. Enquanto Ted foi contra o código de marcação complexo, links quebrados, e muitos outros problemas associados com o HTML tradicional na WWW, muito das aplicações criadas para o WWW foi elaborado a partir do trabalho de Ted. Ainda há conflito em torno das aplicações e exatamente por isso que o Projeto Xanadu não conseguiu decolar.
Notas de Ted Nelson:
1. Ninguém nunca me pagou para ser um visionário.
2. Eu não acredito que tenha usado o termo "máquinas literárias" até 1981, quando dei esse nome ao título de meu livro. No entanto, 1965 é quando pela primeira vez usei a palavra "hipertexto".
3. É fundamental ressaltar que a visão de Tim de hipertexto (apenas ligações de sentido único, invisível não permitiu a sobreposição) é totalmente diferente da minha (visível, unbreaking n-way links de todas as partes, todo o conteúdo legalmente reweavable por qualquer pessoa em novos documentos com os caminhos de volta aos originais, e transclusões como links - como na visão original de Vannevar Bush).
4. Voltando ao site original não deve ser feito através de links, mas deve ser feito por meio facilitado. O mecanismo de ligação, particularmente no link embutido da Web, não pode fazer isso corretamente.
5. "Futurista" é uma daquelas palavras que implica que uma idéia não é uma possibilidade - apenas um sonho louco, e, portanto, apenas uma inspiração. Acredito que Tim achava que tinha as ideias mais concretas, enquanto eu acho que ele simplifica elas - com a extrema complexidade de resultado que é hoje.
6. "Xanadu" é uma marca registada que eu mantenho a um custo considerável, e peço a todas as partes a respeitar isso usando o ® "ou" (R) "símbolo para o primeiro uso da marca" Xanadu "em cada documento.
7. Não é "a informação de todo o mundo", mas os documentos de todo o mundo. O conceito de "informação" é discutível, documentos e muito menos assim. Creio que Tim está encontrando o seu conceito de informação pura, a "Web Semântica", muito mais difícil de alcançar do que documentos de hipertexto.
8. Não, não é um link; um caminho transclusive. Os dois mecanismos são completamente diferentes. Um link conecta duas coisas que são diferentes. A transclusão conecta duas coisas que são as mesmas.
9. Não é sempre os autores titulares de direitos. Às vezes, o autor é titular de direitos, outras vezes não. Um titular de direitos é geralmente alguém que tenha comprado ou contratado, os direitos do autor. Enquanto não temos preocupação sentimental para os autores, no nosso sistema de direito titular pode ser qualquer um, assim como o proprietário da terra é raramente o colono original. Além da justiça aos autores e artistas, um objectivo fundamental é trazer os titulares dos direitos comerciais - grandes editoras, as editoras universitárias, estúdios de cinema - que não tera outra forma de publicar seu conteúdo digital. Muitas pessoas pensam que eu sou contra conteúdo gratuito; absurdo. Quero criar um mundo compartilhado de conteúdos mixado entre gratuitos e pagos.
10. Não, não todas as vezes que ele foi lido (pay-per-view), mas a primeira vez que comprou, como acontece com um documento em papel.
11. "Utópico" é outro sinônimo de "impossível", como "futurista" na nota 5. Isto mostra um problema de entendimento.
12. "Comunicadas como iguais" é uma expressão graciosa mas confusa. O autor e o leitor não são exatamente iguais, que ocupam diferentes papéis com conflitos frequentes. Se ele quer dizer que qualquer um pode ser um autor e qualquer um pode ser um leitor, que sempre foi verdade (já que a auto-publicação tem sido sempre respeitável). Eu diria que se "dividiu um level playing field". Mas eu aprecio o espírito desta expressão.
Tim Berners-Lee:

Sem dúvida, o pai do hipertexto, Tim Berners Lee, portanto, com base em estudos dos dois homens anteriormente citados no site, construiu o que hoje é conhecida como a World Wide Web.
Ele juntou a parte teórica da noção de hipertexto com a parte prática dos protocolos TCP e DNS para gerar o que hoje a gente entende como WWW.
Originário de Londres, Tim Berners Lee atingiu os seus estudos de Física em 1976, fortemente influenciados por matemáticos e seus pais, continuou seus estudos na Emanuel School em Wandsworth. Entre suas invenções mais inovadoras são: Um TTL circuito ordenador basado, um processador Motorola 68000 e um sistema operacional chamado INQUIRE.
Ele foi apontado como o pai do design de hipertexto linguagem de programação HTML, o protocolo HTTP e da localização do URL do sistema e uma completa infra-estrutura completa para a criação de páginas da Web de hoje e seus respectivos meios de comunicação, sem sair da globalização da ligação à Internet porque Tim usava servidor Web do mundo e a primeira chamada NeXTcube.
Tim Berners-Lee. Foi quem inventou a World Wide Web, a "teia do tamanho do mundo", conhecida pela sigla www. O homem, enfim, é o pai da web. Mas não quis patentear o invento. "Ela é uma criação social, e não um brinquedinho", escreveu Berners-Lee, no fim dos anos 90. Hoje, o físico garante que não se arrepende da decisão, que poderia tê-lo tornado biliardário. Atualmente, ele se dedica a aprimorar ainda mais os recursos da rede e está à frente do projeto da "web semântica". Berners-Lee acredita que essa nova versão aumentará consideravelmente as possibilidades da internet, pois torna possível o cruzamento de dados que hoje ficam confinados em programas diferentes.
Formado em engenharia de sistemas, com larga experiência em telecomunicações e em programação de editores de texto, este europeu concebeu a World Wide Web em 1989, no âmbito do trabalho de apoio aos sistemas de documentação e colaboração entre investigadores e cientistas do Centro Europeu de Pesquisa Nuclear (CERN, baseado na Suíça).
Berners-Lee colaborou esporadicamente com o CERN durante os anos 80, sobretudo devido às suas competências no âmbito dos sistemas de documentação electrónica. No fim dos anos 80, a invenção da Web foi um caso do homem certo no momento certo, resolvendo o problema certo no ambiente certo e mudando o mundo para sempre.
O problema era este: o CERN era (e é) um esforço internacional de investigação e desenvolvimento, sendo suposta a colaboração e partilha de conhecimentos permanentes entre os diversos participantes em dezenas de projetos de investigação. Ora, estas pessoas não passavam a vida na Suíça e a maior parte do trabalho real de investigação era desenvolvido fora das paredes do instituto. Assim, a partilha de conhecimentos e a “transferência de tecnologia” era levada a cabo usando comunicações e publicações em papel, com todas as enormes inconveniências associadas (não vamos entrar nesta análise...). Era preciso arranjar uma plataforma qualquer de publicação, em princípio em formato electrónico, que ajudasse a resolver o imbróglio e permitisse um acesso facilitado à informação.

O papel de Berners-Lee era tentar avançar com pistas que permitissem vir a ultrapassar esta situação. Ele conhecia bem o conceito de hipertexto, que existe desde os anos 60 (podendo mesmo argumentar-se que pelo menos desde 1945 se discute o assunto) e estava já profusamente estudado e até implementado, nomeadamente em sistemas de ajuda dos Apple e em cd-roms com material de referência. O hipertexto era já a tecnologia consagrada para a organização e apresentação de material escrito em formato electrónico. Parecia óbvio que o sistema teria de passar por esta tecnologia. Mas isto era só uma parte do problema.
A outra era a separação geográfica de toda aquela gente e o facto inescapável de todos usarem sistemas de informação diferentes e incompatíveis. A plataforma de comunicação que eles usavam preferencialmente era a Internet, então perfeitamente disseminada por tudo o que era universidade e instituto de investigação do mundo, e que parecia portanto ser a única porta aberta para uma solução global. Mas a Internet era, em termos práticos, pouco mais do que uma ferramenta para troca de correspondência e disponibilização de ficheiros. Havia um protocolo emergente para arrumação hierárquica de informação (o Gopher), mas não servia para os desígnios de Tim Berners-Lee.
A solução acabou por surgir, não num momento de inspiração divina, mas da forma habitual: com dedicação e suor. Tinha o inconveniente de obrigar os utilizadores a codificar os seus documentos num formato específico, onde o texto seria pontuado por códigos (etiquetas – tags) de controlo, de acordo com regras específicas (para definir estas regras, Berners-Lee baseou-se no SGML, uma invenção da IBM para “descrição” em abstrato da estrutura de conteúdos): ao conjunto das regras chamou-se HTML.
Estes documentos seriam gravados no disco rígido de um computador com acesso permanente à Internet (o que era o habitual nesses meios: os computadores com acesso à Internet tinham acesso permanente). Cada um deles seria dotado de uma localização específica, definida a partir do seu nome de ficheiro no disco rígido, da estrutura de directórios e do domínio ou endereço IP (sempre únicos) em que se encontrava enquadrado. Essa localização, a que se acrescenta ainda o protocolo de acesso à informação, levou o nome de URL.
Era necessário criar um novo protocolo que permitisse o acesso adequado à informação neste formato e o seu carregamento. O protocolo é o HTTP.
Genial foi a inclusão de uma etiqueta graças à qual as ligações hipertextuais (links) entre documentos dependeria dos URLs. Como estes haviam sido desenhados para descrever um qualquer documento numa qualquer máquina, estava estabelecida uma plataforma que permitiria à partida, ligar qualquer documento a qualquer outro. Esta possibilidade de referências automáticas a outros documentos (assumindo que eles permaneceriam no mesmo sítio...) era uma característica preciosa para os investigadores, que tipicamente têm de se haver com milhares de referências...
Para tornar isto tudo uma realidade, era agora necessário passar à prática, o que significava arranjar um engenheiro. Com a ajuda de Robert Cailliau, Tim Berners-Lee criou um servidor e um cliente (um browser...) para o seu protocolo e começou a experimentar a coisa. Para popularizar o sistema, desenvolveu-se ainda uma aplicação que convertia com relativa facilidade documentação já existente para o novo formato. Estávamos em 1991 e nos dois anos seguintes a nova facilidade de disponibilização automática de informação tornou-se muito popular entre a comunidade de físicos nucleares. Bastava-lhes colocar os seus relatórios numa máquina do seu sistema, avisar por correio-e a sua disponibilidade e o seu URL, e quem estivesse interessado, podia facilmente aceder à informação, sem qualquer necessidade de usar o “dead-tree stuff” (o papel...).
Tudo isto foi desenvolvido de acordo com as “normas” e a “etiqueta” da Internet, o que queria dizer que todo o corpo teórico subjacente a esta invenção era de domínio público. No decorrer do ano seguinte, um jovem estudante universitário norte-americano experimentou o cliente de Berners-Lee e comentou para os seus botões qualquer coisa como: “Cool!... Hmm, I think I can make better than this...” Alguns meses depois, havia um browser, também gratuito, para Windows, o mais popular sistema operativo do mundo. Ao browser, chamado Mosaic, juntou-se, para a maior parte dos utilizadores, um pequeno shareware australiano (o Trumpet Winsock, criado por um programador da Tasmânia!) muito eficiente na resolução do problema do acesso à Internet por modem, de um computador com o Windows 3.1 (naquela altura, o acesso à Internet ainda não estava incorporado no sistema operativo; claro que esta oportunidade de negócio acabou por ser anulada pela Microsoft, como é tradição). Agora Tim Berners-Lee se dedica a divulgar a web semântica.
 E como soa dizer-se, o resto é história. Ao contrário de quase todos os outros, Tim Berners-Lee escolheu não ficar podre de rico. Preferiu orientar a sua vida para o acompanhamento rigoroso da sua invenção, para lhe assegurar um lugar sólido no panteão das conquistas da humanidade. A estratégia, desse ponto de vista, parece estar a frutificar. A TIME, por exemplo ( no artigo), considera-o um dos 20 mais importantes cientistas (e uma das 100 pessoas mais influentes) do nosso século, ao lado de Einstein (relatividade), Fleming (penicilina), Turing (computador) ou Freud (psicanálise), entre outros.
E como soa dizer-se, o resto é história. Ao contrário de quase todos os outros, Tim Berners-Lee escolheu não ficar podre de rico. Preferiu orientar a sua vida para o acompanhamento rigoroso da sua invenção, para lhe assegurar um lugar sólido no panteão das conquistas da humanidade. A estratégia, desse ponto de vista, parece estar a frutificar. A TIME, por exemplo ( no artigo), considera-o um dos 20 mais importantes cientistas (e uma das 100 pessoas mais influentes) do nosso século, ao lado de Einstein (relatividade), Fleming (penicilina), Turing (computador) ou Freud (psicanálise), entre outros.

Em 1994, Tim Berners-Lee fundou o World Wide Web Consortium (W3C), no Instituto de Tecnologia de Massachusetts, com suporte do CERN, DARPA (como foi renomeada a ARPA) e da Comissão Europeia. A visão da W3C era a de padronizar os protocolos e tecnologias usados para criar a web de modo que o conteúdo possa ser acessado largamente pela população mundial tanto quanto o possível.
Durante os próximas anos, o W3C publicou várias especificações (chamadas “recomendaçções”) incluindo o HTML, o formato de imagens PNG, e as Folhas de Estilo em Cascata versões 1 e 2.
Entretanto, a W3C não obriga ninguém a seguir suas recomendações. Os fabricantes precisam adotar os documentos da W3C apenas se eles quiserem etiquetar que seus produtos como complacentes com a W3C. Na prática, isto não tem muito valor mercadologicamente já que a maioria dos usuários da web não sabem, nem provavelmente se importam com, quem é a W3C. Em consequência disto, a “guerra dos navegadores” continuou inabalável.
Para saber mais O melhor é começar por ler o livro de Berners-Lee, onde ele conta melhor do que ninguém a sua aventura. Se tem dificuldades com o inglês, o sítio do CERN inclui uma versão em francês da história da criação da Web. Em Dezembro de 1997, a Scientific American publicou um perfil do inventor. Outro perfil interessante é o traçado pelo próprio nas páginas da revista Forbes, uma revista sobre fortunas e negócios, onde ele tenta explicar que o dinheiro não é tudo na vida.
Advanced Research Projects Agency Network:
ARPANet, acrônimo em inglês de Advanced Research Projects Agency Network (ARPANet) do Departamento de Defesa dos Estados Unidos da América, foi a primeira rede operacional de computadores à base de comutação de pacotes, e o precursor da Internet.
ARPANet é a rede que levou à internet onde ela esta hoje. A Wikipédia possui um artigo muito bom sobre a ARPANET e o Google Video tem um vídeo interessante sobre a ARPANet 1972.
Tim Berners-Lee:
Videos de Tim Berners-Lee:tim berners lee on the next web ptbr
Fontes de pesquisa: suapesquisa estudar.org ibiblio w3.org/People Berners-Lee veja.abril.com.br/especiais tecnologia
Resumo para entender sobre a Historia dos Motores de Busca
Os motores de busca apareceram pouco tempo após o aparecimento da Internet, com intenção de prestar um serviço muito importante (ex:. a busca de qualquer informação na internet etc). Através do aparecimento dos motores de busca, desenvolveram-se diversas empresas (ex:. google, yahoo, sapo, msn agora Bing etc).
Os primeiros motores de busca (Yahoo) baseavam-se na indexação de páginas através da sua categorização. A mais recente geração de motores de busca (Google) utiliza outras diversas tecnologias, como, a procura por palavras-chave directamente nas páginas, o uso de referências externas espalhadas pela web.
A primeira ferramenta utilizada para busca na Internet foi o Archie, o programa baixava as listas de directório de todos arquivos localizados em sites públicos criando uma base de dados que permitia busca por nome de arquivos.
O que é um site de busca ou motor de busca?
O site de busca ou motor de busca é um sistema idealizado para encontrar informações localizadas na web a partir de palavras-chave indicadas pelo utilizador, reduzindo o tempo necessário para encontar informação.
Os motores de busca surgiram logo após o aparecimento da Internet, com a intenção de prestar um serviço extremamente importante: a busca de qualquer informação na rede, apresentando os resultados de uma forma organizada, e também com a proposta de fazer isto de uma maneira rápida e eficiente. A partir deste preceito básico, diversas empresas se desenvolveram, chegando algumas a valer milhões. Entre as maiores empresas encontram-se o Google, o Yahoo, o aeiou entre outros. Os primeiros motores de busca como o Yahoo baseavam-se na indexação de páginas através da sua categorização. Posteriormente surgiram as meta-buscas. A mais recente geração de motores de busca (como a do Google) utiliza tecnologias diversas, como a procura por palavras-chave directamente nas páginas e o uso de referências externas espalhadas pela web, permitindo até a tradução de páginas para a língua do utilizador. O Google, além de fazer a busca pela Internet, oferece também o recurso de se efetuar a busca somente dentro de um site específico.
Mais Sobre a historia dos sites de busca, motor de busca, motor de pesquisa ou máquina de busca
Os primeiros motores de busca (como o Yahoo) baseavam-se na indexação de páginas através da sua categorização. Posteriormente surgiram as meta-buscas. A mais recente geração de motores de busca (como a do Google) utiliza tecnologias diversas, como a procura por palavras-chave directamente nas páginas e o uso de referências externas espalhadas pela web, permitindo até a tradução directa de páginas (embora de forma básica ou errada) para a língua do utilizador. O Google, além de fazer a busca pela Internet, oferece também o recurso de se efetuar a busca somente dentro de um site específico. É essa a ferramenta usada na comunidade Wiki.
Os motores de busca são buscadores que baseiam sua coleta de páginas em um robô que varre a Internet à procura de páginas novas para introduzir em sua base de dados automaticamente. Motores de busca típicos são Google, Yahoo e Altavista.
A primeira ferramenta utilizada para busca na Internet foi o Archie (da palavra em Inglês, "archive" sem a letra "v"). Foi criado em 1990 por Alan Emtage, um estudante da McGill University em Montreal. O programa baixava as listas de diretório de todos arquivos localizados em sites públicos de FTP (File Transfer Protocol) anônimos, criando uma base de dados que permitia busca por nome de arquivos.
Enquanto o Archie indexava arquivos de computador, o Gopher indexava documentos de texto. Ele foi criado em 1991, por Mark McCahill da University of Minnesota, cujo nome veio do mascote da escola. Devido ao fato de serem arquivos de texto, a maior parte dos sites Gopher tornaram-se websites após a criação da World Wide Web.
Dois outros programas, Veronica e Jughead, buscavam os arquivos armazenados nos sistemas de índice do Gopher. Veronica (Very Easy Rodent-Oriented Net-wide Index to Computerized Archives) provia uma busca por palavras para a maioria dos títulos de menu em todas listas do Gopher. Jughead (Jonzy's Universal Gopher Hierarchy Excavation And Display) era uma ferramenta para obter informações de menu de vários servidores Gopher.
O primeiro search engine Web foi o Wandex, um índice atualmente extinto feito pela World Wide Web Wanderer, um web crawler (programa automatizado que acessa e percorre os sites seguindo os links presentes nas páginas.) desenvolvido por Matthew Gray no MIT, em 1993. Outro sistema antigo, Aliweb, também apareceu no mesmo ano e existe até hoje. O primeiro sistema "full text" baseado em crawler foi o WebCrawler, que saiu em 1994. Ao contrário de seus predecessores, ele permite aos usuários buscar por qualquer palavra em qualquer página, o que tornou-se padrão para todos serviços de busca desde então. Também foi o primeiro a ser conhecido pelo grande público. Ainda em 1994, o Lycos (que começou na Carnegie Mellon University) foi lançado e tornou-se um grande sucesso comercial.
Logo depois, muitos sistemas apareceram, incluindo Excite, Infoseek, Inktomi, Northern Light, e AltaVista. De certa forma, eles competiram com diretórios populares como o Yahoo!. Posteriormente, os diretórios integraram ou adicionaram a tecnologia de search engine para maior funcionalidade.
Os sistemas de busca também eram conhecidos como a "mina de ouro" no frenêsi de investimento na Internet que ocorreu no fim dos anos 1990s. Várias empresas entraram no mercado de forma espetacular, com recorde em ganhos durante seus primeiros anos de existência. Algumas fecharam seu sistema público, e estão oferecendo versões corporativas somente, como a Northern Light.
Mais recentemente, os sistemas de busca também estão utilizando XML ou RSS, permitindo indexar dados de sites com eficácia, sem a necessidade de um crawler complexo. Os sites simplesmente provêm um xml feed o qual é indexado pelo sistema de busca. Os XML feeds estão sendo cada vez mais fornecidos de forma automática por weblogs. Exemplos são o feedster, que inclui o LjFind Search que provê serviços para os blogs do site LiveJournal.
O primeiro site de busca
O primeiro site de busca: Archie (1990)
Em 1990, na Universidade McGill de Montreal, Alan Emtage contribuio muito para a historia do site de busca criando Archie, o primeiro site de busca usado na ineternet, o processo de busca pela informação era dificil e demorado. A internet era uma coleção de servidores FTP(File TransferProtocol) interconectados que disponibilizava espaço para o download e upload de arquivos. A primeira ferramenta da historia dos sites utilizada para busca na Internet foi chamado de "Archie". (O nome significa "arquivos"). O programa baixava as listas de diretório de todos os arquivos localizados em sites públicos de FTP (File Transfer Protocol) sites, criando um banco de dados pesquisável de nomes de arquivos.
Existe uma imensa gama de arquivos e softwares disponíveis em toda a rede e que provém informações nas mais diversas áreas. Archie é o recurso na internet que permite descobrir exatamente onde estão localizados estes arquivos e programas.
Como funciona? O Archie é um grande compilador de listas de nomes de arquivos disponíveis em áreas de ftp anônimo. Suas bases de dados de uso público são mantidas em mais de 30 diferentes locais. O Archie foi originalmente desenvolvido na McGill University em Montreal e agora está sendo distribuído pela Bunyip Information Systems.
Ao fazer uma busca através de um servidor Archie, você estará solicitando a este servidor que procure em sua base de dados arquivos com uma expressão ou palavra. Este servidor responderá com uma lista de arquivos e diretórios que contenham essa expressão/palavra, informando também onde eles estão localizados e demais detalhes para uma transferência.
O Archie é particularmente útil para se encontrar softwares de acesso público disponíveis em rede e pode ser acessado de várias formas:
- Conexão telnet
- Correio eletrônico
- Gopher gateway
- Interface WWW
Para encontrar uma informação desejada era necessário por parte dos usuários a navegação através de cada arquivo ou a indicação da exata localização por outro usuários. Archie armazenava e indexava em um banco de dados todas as listagens de diretórios de arquivos disponibilizados em redes de servidores FTP anônimos, facilitando a sua localização pelos seus usuários. A história sobre os sites de busca começou em 1993 e a maioria deles foram para uso em faculdades, mas muito antes da maioria deles veio o Archie. O primeiro site de busca criado foi Archie, criado em 1990 por Alan Emtage, um estudante da Universidade McGill, em Montreal. A intenção original do nome era "arquivos", mas foi encurtado para Archie.Archie ajudou a resolver esse problema de dispersão de dados através da combinação de um roteiro baseado em dados do coletor com uma correspondência de expressões regulares para recuperar nomes de arquivos que correspondem à uma consulta do usuário. Essencialmente Archie tornou-se um banco de dados de nomes de arquivos na Web que iria corresponder com as consultas de usuários.
Leia mais sobre Archie
História do site de busca Gopher
História do site de busca Gopher começou em 1991 com Mark MacCahill, estudante da universidade de Minesota evoluio este sistema para busca de (strings) o que na época chamou de GOPHER, documentava arquivos no formato de texto simples, que posteriormente tornaram-se os primeiros sites da web publica, porem mesmo com as capacidades individuais e fantásticas destes buscadores em particular, não supriam ainda todo o potencial da web.
Gopher oferece arquivos para download com alguma descrição do conteúdo para tornar mais fácil de ser encontrado o arquivo que você precisa ou procura. Os arquivos são organizados no computador remoto em uma maneira hierárquica, bem como nos arquivos do disco rígido de seu computador. Este protocolo não é mais amplamente usado , mas você ainda pode encontrar alguns sites gopher operacional.
Gopher foi utilizado na Internet antes da Web tornar-se popular. Normalmente Gopher é o modo somente texto, sem imagens, sem multimídia, e não permite scripts (JavaScript / JScript, VBScript, Java, e assim por diante). Não há fotos grandes, mas a vantagem de navegar em modo texto é que ele funciona muito mais rápido para o cliente não tem que transferir grandes arquivos gráficos, só texto e em modo texto é mais fácil encontrar o que você precisa. Se você está realmente à procura de informações e não apenas andando na web sem saber o que fazer em seguida, as imagens não são importantes, e você só precisa de texto - exceto (talvez) que você esteja procurando algumas fotos especiais ou fotografias. Alguns fãs ainda estão trabalho sobre protocolo Gopher e há ainda suporte para 3D nas últimas versões, mas Gopher não é amplamente usado hoje - não é tão popular como a Web onde o usuário pode apenas dar um clique, clique, clique, sem pensar o porquê do clique.
Um exemplo de uma janela Gopher:
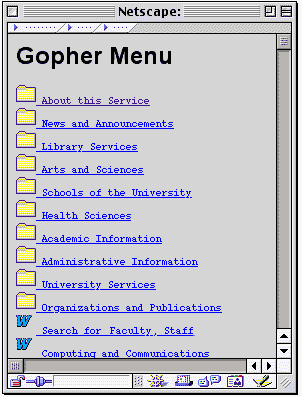
Em 1991, Mark McCahill, da universidade de Minessota, criou Gopher, (O programa foi nomeado com o nome do mascote da escola). Eram arquivos de texto, a maioria dos sites Gopher tornaram-se Web sites após a criação da World Wide Web. Gopher era um programa que indexava o conteúdo de documentos de texto, que futuramente se tornariam os arquivos dos primeiros web sites da internet pública, época em que os servidores HTTP se tornariam mais populares que os servidores FTP. Gopher teve o apoio dos programas Veronica (Very Easy Rodent-Oriented Net-wide Index to Computadorized Archives) e Jughead (Jozys’s Universal Gopher Hierarchy Excavation and Display) para referenciar os índices criados, fazendo buscas dentro dos arquivos armazenados, e assim permitindo aos usuários realizar buscas diretamente no índice, através da indicação de palavras-chaves. Em 1989, McCahill liderou a equipe da Universidade de Minnesota, que desenvolveu na Internet o primeiro cliente de e-mail populares o PopMail, para o Macintosh (e depois o PC).Leia mais sobre Mark McCahill



Leia mais sobre Gopher
Historia do site de busca Wandex
Desde então, as buscas evoluíram e em 1993, Matthew Gray, criou Wandex, oprimeiro sistema de busca que indexava e também buscava no índice da web pages. Sua tecnologia se tornou a base de todos os buscadores atuais, cujo software usa aplicações para coletar e armazenar em bancos de dados informações sobre web pages.Um sistema de busca possui uma interface onde seus usuários digitam um termo, uma palavra-chave ou frase, na tentativa de encontrar uma informação específica. Um algoritmo do sistema examina as informações armazenadas e retorna links de web pages em que o conteúdo parece combinar com o termo digitado.
A precisão dos resultados varia de acordo com o algoritmo usado. O processo de coleta das informações referentes às web pages é realizado por um agente conhecido como crawler, spider, ou robô, que literalmente analiza cada URL (Universal Resource Locator) na web e coleta de cada web page palavras-chaves e frases-chave.
Wandex Matthew Gray's (1993) o primeiro motor de busca foi projetado para acompanhar o crescimento da Internet. Inicialmente, contava apenas servidores Web, mas depois também começou a capturar URLs. Wandex explorou a natureza associada da Web, seguindo um link para o próximo período de um procedimento que ainda é seguido por modernos motores de busca.
O armazenamento e a recuperação dos dados depende dos métodos adotados por cada sistema de busca, e o ranking dos resultados mostrados depende dos critérios utilizados. Diferentes sistemas de busca usam diferentes critérios de rankings. Por esta razão uma pesquisa por palavra ou frase em diferentes sistemas de busca gera diferentes resultados. O SEO foi idealizado como uma estratégia de marketing online que procura customizar os web sites a fim de manipular os sistema de busca, objetivando o melhor ranking possível, podendo assim gerar resultados consideráveis como aumento de tráfego, redução de custos e visibilidade através das primeiras posições nos resultados
Leia mais sobre Wandex
Em 1993, Martijn Koster criava Aliweb (Archie-Like Indexing da Web). Aliweb permitiu que os usuários enviem suas próprias páginas a serem indexadas. Segundo Koster, "Aliweb foi um motor de busca com base na meta automatizado de coleta de dados, para a web."
Eventualmente, como parecia que a Web pode ser rentável, os investidores começaram a se envolver na historia dos sites de busca e os sites de busca tornaram-se grande um negócio.

Excite foi introduzido em 1993 por seis estudantes da Universidade de Stanford. Usou-se análise estatística de relações de palavra para auxiliar no processo de busca. Dentro de um ano, Excite foi constituída e entrou em operação em dezembro de 1995. Hoje é uma parte da empresa AskJeeves.

EINet Galaxy (Galáxia) foi criada em 1994 como parte do Consórcio de Pesquisa MCC na Universidade do Texas, em Austin. Ele acabou por ser adquirido na Universidade e, depois de ser transferido através de várias empresas, é uma empresa separada hoje. Ele foi criado como um diretório, contendo, Gopher e Telnet recursos de pesquisa para além da sua funcionalidade de busca na web.

A Yahoo! Inc. é uma empresa norte-americana de serviços de Internet com a missão de ser "o serviço de Internet global mais essencial para consumidores e negócios". Opera um portal de Internet, um diretório web, e outros serviços, incluindo o popular Yahoo! Mail. Foi fundado por David Filo e Jerry Yang, formandos da Universidade de Stanford em janeiro de 1994 e incorporado no dia 2 de março de 1995. A sede da empresa é em Sunnyvale, Califórnia.
Jerry Yang e David Filo criadores do site de busca Yahoo, criado em 1994. Ele começou como uma lista de seus sites favoritos. O que fez a diferença foi que cada entrada ia para além da URL, também teve uma descrição da página encontrada. Dentro de um ano a dois e depois de alguns financiamentos recebidos a Yahoo empresa, foi criada.
Leia mais sobre a Historia do site de busca Yahoo


Brian Pinkerton, da Universidade de Washington lançou WebCrawler em 20 de Abril de 1994. Ele foi o primeiro rastreador que indexava páginas inteiras. Em breve tornou-se tão popular que durante o horário diurno poderia não ser utilizada. AOL eventualmente adquiridos WebCrawler e ele ficou em sua rede. WebCrawler abriu a porta para muitos outros serviços a seguir como o naipe. No prazo de 1 ano veio Lycos, Infoseek e OpenText.
Mais tarde, em 1994, WebCrawler foi introduzido. Foi o primeiro motor de pesquisa de texto completo na Internet, todo o texto de cada página foi indexada pela primeira vez.
![[LYCOS]](https://www.nih.gov/catalyst/back/95.09/lycos.gif)

Lycos foi o desenvolvimento de pesquisa principais, tendo sido contruido na Carnegie Mellon University em torno de Julho de 1994. Michale Mauldin era responsável por este site de busca e continua a ser o cientista chefe no Lycos Inc.
Em 20 de Julho de 1994, fui ligado a rede públicoacom um catálogo de 54.000 documentos Lycos. Além de fornecer classificados recuperação de relevância, Lycos tinha correspondência de prefixo e palavra bônus de proximidade. Mas a principal diferença dos Lycos foi o tamanho do seu catálogo: em Agosto de 1994, Lycos identificou 394,000 documentos; em Janeiro de 1995, o catálogo atingiu 1,5 milhão de documentos; e em Novembro de 1996, Lycos tinha indexado mais de 60 milhões de documentos--mais do que qualquer outro mecanismo de busca da Web. Em Outubro de 1994, Lycos, primeira classificada na lista do Netscape dos site de busca por encontrar a maioria dos acertos na palavra navegar.
Lycos apresenta recuperação de relevância, a correspondência de prefixo, e da proximidade de palavras, em 1994. Foi um grande mecanismo de busca, indexação de mais de 60 milhões de documentos em 1996, o maior de qualquer motor de busca ao mesmo tempo. Como muitos dos outros motores de busca, Lycos foi criado em um ambiente universitário da Universidade Carnegie Mellon pelo Dr. Michael Mauldin.
![[INFOSEEK]](https://www.nih.gov/catalyst/back/95.09/infoseek.gif)
O site de busca Infoseek entrou em operação em 1995. Ele realmente não traz nada de novo à cena do motor de busca. É agora propriedade da Walt Disney Internet Group e o domínio encaminhado para Go.com.

Alta Vista também começou em 1995. Foi o primeiro motor de pesquisa que permitiria uma busca de linguagem natural e usava avançadas técnicas de investigação. Ela também fornece uma pesquisa de multimídia para fotos, músicas e vídeos.
AltaVista trouxe muitos recursos importantes para a web. Tinham quase ilimitada largura de banda (para a época), eles foram os primeiros a permitir consultas de linguagem natural, pesquisa de técnicas avançadas e permitido aos usuários adicionar ou excluir seu próprio URL dentro de 24 horas. Sequer era verificado o link de entrada. AltaVista também forneceu inúmeras dicas de pesquisa e recursos de pesquisa avançada.
Devido à má gestão, um medo de manipulação do resultado e portal com muita desorganização AltaVista foi amplamente orientada em irrelevancy na época Inktomi e Google começou a se tornar popular. Em 18 de Fevereiro de 2003, Overture assinou uma carta de intenções para comprar AltaVista. Após Yahoo! comprar a Overture eles melhoraram algumas das tecnologias do AltaVista no Yahoo! Search e ocasionalmente usam AltaVista como uma plataforma de teste.
Leia mais sobre a Historia do site de busca Alta Vista
.
Looksmart foi fundada em 1995. Esse site de busca competiu com o site de busca do Yahoo!, frequentemente aumentando suas taxas de inclusão para frente e para trás. Em 2002, Looksmart inovou em um pagamento por clique em provedor, que cobrada uma taxa fixa por clique de sites listados. Que causou o desaparecimento da boa fé e lealdade que haviam constituído, embora ele permitiu fazer lucro por distribuir listagens pagas para alguns grandes portais como o MSN. O problema era que a Looksmart se tornou muito dependente do MSN e em 2003, quando a Microsoft anunciou que eles eram dumping Looksmart basicamente matou seu modelo de negócios.

A corporação Inktomi surgiu em 20 de Maio de 1996 na historia dos sites de busca com o seu motor de busca Hotbot. Criada Inktomi a melhor tecnologia adquirida em suas pesquisas. Tornou extremamente popular rapidamente.
Em Outubro de 2001, Danny Sullivan escreveu um artigo intitulado Inktomi correio publicitário não solicitado de banco de dados à esquerda aberta para pública, que destaca como Inktomi acidentalmente permitio ao público acessar seu banco de dados de sites de spam, 1 milhão de URLs.
Embora pioneira Inktomi o modelo de inclusão paga era longe tão eficiente quanto o pagamento por clique em modelo de leilão desenvolvido pela Overture. Seus resultados de pesquisa de licenciamento também não era rentável o suficiente para pagar suas despesas de dimensionamento. Eles não conseguiram desenvolver um modelo de negócios rentáveis e foi vendidos a Yahoo! por aproximadamente US $ 235 milhões.
Inktomi começou em 1996 na Universidade de Berkeley. Em junho de 1999 Inktomi introduzido um mecanismo de pesquisa de diretório powered by "indução" conceito de tecnologia. "Indução Concept", segundo a empresa, "tem a experiência de análise humana e aplica os mesmos hábitos de uma análise computadorizada de vínculos, uso e outros padrões para determinar quais sites são mais populares e os mais produtivos." Inktomi foi comprado pelo Yahoo em 2003.
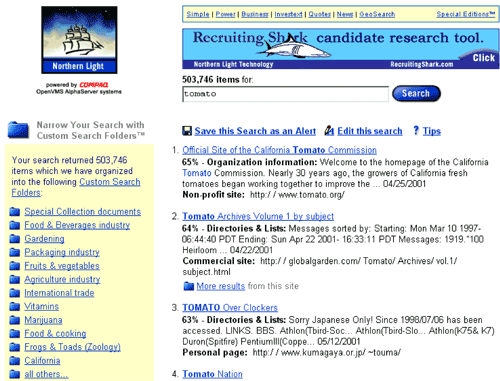
Eu realmente gostei da maneira que os resultados do site de busca Northern Light classificava, o site apresentava em categorias diferentes, e por alguns anos eu buscava no Northern Light para encontrar páginas que eu poderia ter perdido e não encontrado como no site de busca google.

Google foi lançada em 1997 por Sergey Brin e Larry Page, como parte de um projeto de pesquisa na Universidade de Stanford. Ele usa as ligações de entrada para classificar sites. O Google percorreu um longo caminho em seus onze anos de história, desde o seu “início humilde”, como um projeto de investigação da Universidade de Stanford, em 1998, à escala global e sua multibilionária presença na internet atual.
A empresa celebrou o seu 11 º aniversário e escolheu marcar a ocasião com um novo Google Doodle, a famosa mudança em seu logo. Dessa vez, eles colocaram um L extra para que o nome da empresa formasse um número “11”.
A data real de fundação do Google é assunto de debate. Há aqueles que pensam que o Google deve sempre cortar o bolo em 4 de setembro, dia em que o portal apresentou seus documentos constitutivos e tornou-se oficialmente o Google, Inc, em 1998. Outros ainda pensam que a empresa deve reconhecer o 15 de setembro de 1997 como sua data de fundação, pois foi nessa época que a companhia registrou o domínio google.com. Mas, apesar das dúvidas, a companhia comemora seu aniversário em 27 de setembro há alguns anos, data que já se tornou oficial.Leia mais sobre a Historia do site de busca Google

 Em Abril de 1997, Ask Jeeves foi lançado como um mecanismo de pesquisa de linguagem natural. Jeeves usava editores humanos para tentar corresponder consultas de pesquisa. Peça foi alimentado por DirectHit por um tempo, que pretendia ter resultados baseados em sua popularidade, mas essa tecnologia provou fácil de spam como o componente central de algoritmo. Em 2000 o motor de busca Teoma foi lançado, que usa clusters para organizar sites por popularidade específico do assunto, que é outra forma de dizer que tentaram encontrar Comunidades web local. Em 2001, Ask Jeeves comprou Teoma para substituir a tecnologia de pesquisa de DirectHit.
Em Abril de 1997, Ask Jeeves foi lançado como um mecanismo de pesquisa de linguagem natural. Jeeves usava editores humanos para tentar corresponder consultas de pesquisa. Peça foi alimentado por DirectHit por um tempo, que pretendia ter resultados baseados em sua popularidade, mas essa tecnologia provou fácil de spam como o componente central de algoritmo. Em 2000 o motor de busca Teoma foi lançado, que usa clusters para organizar sites por popularidade específico do assunto, que é outra forma de dizer que tentaram encontrar Comunidades web local. Em 2001, Ask Jeeves comprou Teoma para substituir a tecnologia de pesquisa de DirectHit.
Em 4 de Março de 2004, Ask Jeeves concordou em adquirir holdings de pesquisa interativa para 9,3 milhões de ações ordinárias e opções e pagar US$ 150 milhões em dinheiro. Em 21 de Março de 2005, sai do Barry Diller concordou em adquirir fazer Jeeves para 1,85 mil milhões de dólares. IAC possui muitos sites populares como Match.com, Ticketmaster.com e Citysearch.com e está promovendo o Ask entre suas outras propriedades. Em 2006, fazer Jeeves foi renomeado para pedir, e mataram a marca Teoma separada. .
Leia mais sobre a Historia do site de busca Ask

MSN (originalmente The Microsoft Network) é uma coleção de sites de internet e serviços fornecidos pela Microsoft.O Microsoft Network foi lançado como um serviço online e provedor de Internet em 24 de agosto de 1995, para coincidir com o lançamento do sistema operacional Windows 95.
A gama de serviços oferecidos pelo MSN foi alterado desde seu lançamento em 1995. MSN era um um serviço on-line simples para Windows 95, uma experiência precoce de conteúdos multimédia interactivos na Internet, e um dos mais populares provedores de Internet.
A Microsoft utilizou o nome da marca MSN para promover a web popular inúmeros-serviços baseados na década de 1990, principalmente Hotmail e Messenger, antes de reorganização muitos deles em 2005 e 2006 sob outro nome da marca Windows Live. O portal do MSN Internet, MSN.com, ainda oferece uma riqueza de conteúdo e é atualmente um dos domínios de internet mais visitado na Internet.
Em 1998, o MSN Search foi criado mas nunca consegui ser popular como google e yahoo

O site de busca Open Directory também foi criado em 1998. O Open Directory, de acordo com o seu proprio site, "é o maior, e mais completo diretório da web editado. Ele é construído e mantido por uma vasta comunidade global de editores voluntários." Pretende-se tornar o "catálogo definitivo da web." O diretório é mantido pela contribuição humana.
1998 Rich Skrenta e um pequeno grupo de amigos criaram o Open Directory Project, que é um diretório que ninguém pode baixar e usar no todo ou em parte. O PDO (também conhecido como DMOZ) é o maior diretório de internet, quase inteiramente executado por um grupo de editores voluntários. O Open Directory Project foi cultivado fora da frustração webmasters face à espera de ser incluídos no diretório do Yahoo!. Netscape comprou o Open Directory Project em Novembro de 1998. Mais tarde nesse mesmo mês AOL anunciou a intenção de comprar o Netscape em um de 4,5 bilhões de dólares todos os stock lidar.

Este site de busca veio de Karen G. Schneider, que é a diretora do índice de Internet dos bibliotecários. LII é um diretório de elevada qualidade, destinado a bibliotecários. Seu artigo explica como procurar e como adicionar recursos credível de qualidade a LII. A maioria dos outros diretórios, especialmente aqueles que têm uma opção de inclusão paga, mantêm padrões inferiores de catálogos selecionados, criados pelos bibliotecários.
A biblioteca pública de Internet é outro bem mantido pela WWW (World Wide Web)

Devido ao modo de indexação intensivo de executar um diretório e a falta geral de dimensionamento de um modelo de negócios a qualidade e o tamanho dos diretórios acentuadamente cai depois de obter os primeiros resultados da busca. Existem também numerosas indústrias especializadas em site de busca orientada verticalmente, ou localmente. Business.com, por exemplo, é um diretório de sites de negócios.
.

Em Março de 2002, Looksmart comprou um motor de busca pelo nome do WiseNut, https://www.wisenut.com.br/ mas ele nunca ganhou a tração. Looksmart também possui um catálogo de artigos de conteúdo organizado em sites verticais, mas devido à relevância limitada Looksmart perdeu a maioria (se não todos) de sua dinâmica. Em 1998, Looksmart tentou expandir seu diretório comprando o diretório de zelo não comercial de US $ 20 milhões, mas em 28 de Março de 2006, Looksmart encerrar o diretório de zelo na esperança de direcionar tráfego usando Furl, um programa social de marcação.

AllTheWeb - https://www.alltheweb.com/ era uma plataforma de tecnologia de pesquisa iniciada em Maio de 1999 para mostrar as tecnologias de pesquisa rápida. Tinham uma interface de usuário elegante com recursos avançados de pesquisa avançada, mas em 23 de Fevereiro de 2003, AllTheWeb foi comprada pela Overture por 70 milhões de dólares. Após Yahoo! ter comprado eles melhoraram algumas das tecnologias AllTheWeb na Yahoo! Search e ocasionalmente usam AllTheWeb como umaplataforma para testes.
O que é um programa robo da internet:
Segundo o The Web Robots FAQ, "Um robô é um programa que automaticamente atravessa a estrutura do hipertexto da Web, recuperando um documento, recursiva e recuperar todos os documentos que são referenciados. Robôs da Web são por vezes referido como andarilhos da web, crawlers ou spiders. Estes nomes são um pouco enganador porque dá a impressão que o software se move entre os locais como um vírus, este não é o caso, um robô simplesmente visita sites por solicitar os documentos deles. "
Inicialmente, os robôs criaram um pouco de controvérsia, como se usava grandes quantidades de largura de banda, às vezes causando o falhas no servidor. Os robôs mais recentes têm sido otimizadas e agora são usados para a construção de índices muito bem elaborados.
Os sistemas Spiders ou Crawlers visitam automaticamente as páginas da Internet, e as incluem em seus banco de dados. Porém, para uma página ser encontrada automaticamente e ser indexada (lida e incluída no banco de dados), é preciso que ela esteja bem programada, na ótica dos sistemas automatizados dos buscadores Spiders.
Os Crawlers vasculham a Internet e vão adicionando as páginas no banco de dados. Se você alterar sua página, layout ou conteúdo, e os sistemas Crawlers visitarem sua página depois destas mudanças - mais cedo ou mais tarde isso acontece - isto pode e provavelmente vai afetar seu posicionamento nas buscas.
Daí surgiu a necessidade de existirem profissionais e empresas que compreendam o funcionamento dos sites de busca Spiders, que são hoje os mais usados (certamente correspondem a mais de 95% do uso dos sites de busca no mundo), para que os sites sejam corretamente indexados e facilmente encontrados pelas pessoas que procuram por produtos e serviços.
DEPOIS MUITOS SITES DE BUSCA SURGIRÃO
| Ano |
Engine |
Evento |
|
| 1993 |
Wandex |
Lançamento |
|
| 1993 |
Aliweb |
Lançamento |
|
| 1994 |
WebCrawler |
Lançamento |
|
| |
Infoseek |
Lançamento |
|
| |
Lycos |
Lançamento |
|
| 1995 |
AltaVista |
Lançamento (parte do DEC) |
|
| 1995 |
Sapo.pt |
Lançamento |
|
| |
Excite |
Lançamento |
|
| 1996 |
Dogpile |
Lançamento |
|
| |
Inktomi |
Fundado |
|
| |
Ask Jeeves |
Fundado |
|
| 1997 |
Northern Light |
Lançamento |
|
| 1997 |
Sapo.pt |
Fundado |
|
| 1998 |
Google |
Lançamento |
|
| 1999 |
AlltheWeb |
Lançamento |
|
| 1999 |
Baidu |
Fundado |
|
| 2000 |
Singingfish |
Lançamento |
|
| 2000 |
Teoma |
Fundado |
|
| 2000 |
Vivisimo |
Fundado |
|
| 2003 |
Objects Search |
Lançamento |
|
| 2004 |
Yahoo! Search |
Lançamento final |
|
| |
MSN Search |
Lançamento beta |
|
| 2005 |
MSN Search |
Lançamento final |
|
| 2005 |
Bupor |
Lançamento |
|
| 2006 |
Quaero |
Fundado |
|
| 2007 |
Ask.com |
Fundado |
|
| 2007 |
AMGEM Force (16 languages) |
Fundado |
|
| 2008 |
Cuil |
Fundado |
|
| 2009 |
Buscador.com.br |
Fundado |
|
| 2009 |
Bing |
Fundado |
|
| 2009 |
YouNinja.net |
Fundado |
|
| 2009 |
CooBi.netne.net |
Lançado |
|
A Internet é realmente uma das maravilhas que podem levá-lo a qualquer mundo, qualquer campo de conhecimento que você deseja. O problema é por onde começar e como chegar onde você quer. É onde nós precisamos de orientação e ajuda dos "sites de busca". Eles vêm de todas as formas e tamanhos e têm os nomes mais incomuns como: Zabasearch, Altavista, Ask Jeeves, Clickey, Excite e possivelmente o mais famoso de todos, Google. Todos estes sites de busca irá levá-lo para o seu site escolhido em segundos e em seguida, dar-lhe milhares, se não milhões de possibilidades, é realmente fantástico.

A historia dos motores ou sites de busca e a evolução da internet provavelmente teria sido muito diferentes se a tecnologia descrita neste artigo não fosse desenvolvida.
Assim, então como Archie trabalhava? Bem, definitivamente não tem a capacidade dos sites de busca de hoje, mas permitia olhar ao redor da Internet, por exemplo se você soubesse o nome exato de um arquivo que estivesse procurando você talvez o acharia.
Archie não indexava o conteúdo de arquivos de texto. Essa capacidade surgiu em 1991 com o desenvolvimento de um outro site de pesquisa, conhecido como Gopher.
Um documento de 1992, uma comparação de Internet Resource Discovery Approaches, descreve alguns dos programas de indexação surgidos na web, incluindo Archie, e tambem um padrão para procurar chamado de X.500.
X.500 foi um "padrão de um serviço de diretório distribuído " desenvolvido pelo Comité Consultivo Internacional de Telefonia e Telegrafia (incorporada pela União Internacional das Telecomunicações, em 1992) e da Organização Internacional de Normalização (ISO). No entanto, esse padrão parece não permitir o tipo de pesquisas que Archie faz, e foi necessário muito mais trabalho por parte dos hostes de arquivos.
Whois também foi feito para ser melhor que o Archie, mas procurou pessoas, números de rede e domínios na Internet. Foi mais um diretório de informações sobre a rede, uma forma de encontrar arquivos na internet. O documento descreve alguns diretórios interessantes de outros mecanismos de busca
A partir do livro O daemon, o GNU, e o pingüim: A Historia diz um pouco sobre a dimensão e o alcance de Archie: "Em 1992, continha cerca de 2,6 milhões de arquivos com 150 gigabytes de informação . "Pela primeira vez, foi bastante significativo. Problemas de Pesquisa na Internet para Scalable Resource Discovery (PDF), diz-nos que Archie foi muito ativo na época, mas vendo alguns sinais de tensão na manipulação de pesquisas:
A coleção global de servidores Archie processou cerca de 50.000 consultas por dia, gerada por alguns milhares de usuários no mundo inteiro. A cada mês crescia o que requer uma outra réplica de Archie. Uma dúzia de servidores Archie agora reproduzia uma evolução contínua do banco de dados 150 MB de 2,1 milhões de registros. Enquanto ele responde em segundo no sábado à noite, pode demorar cinco minutos a várias horas para responder a perguntas mais simples, durante um dia de semana à tarde.

Claro, a popularidade da World Wide Web mudou muita coisa. Um método precoce de indexação da web, criado por Martijn Koster, que foi um dos principais arquitetos da Norma de Exclusão de Robôs, foi Aliweb. O nome é uma abreviação de Archie-Like Indexing na web. Aliweb não tira completamente a forma como outros motores de pesquisa são, mas o trabalho de Martijn Koster em robôs se tornaria uma parte importante do crescimento dos motores de busca do futuro ".
O mais importante é o fato de que o nosso grupo atual de todos os motores de busca utiliza os seus próprios tipos de tecnologias para gerar resultados, e muitos têm patentes no exato de suas técnicas. Isso não impediu que outros motores de busca aparecessem com suas próprias técnicas. Por exemplo, Direct Hit tem patentes relacionadas ao uso de medidas de cliques para melhorar os resultados. Isso não parou Inktomi,yahoo e outros com o sistema de monitoramento de cliques.
Veronica & Jughead:
Com o boca a boca sobre a propagação do Archie que começou a tornar-se sinonimo de motor de busca Archie tinha tal popularidade que a Universidade de Nevada desenvolveu Veronica. Veronica servia ao mesmo objectivo que Archie, mas trabalhou em arquivos de texto simples. Logo uma outra interface de usuário com o nome de Jughead apareceu com a mesma finalidade de Veronica, ambos foram utilizados para os arquivos enviados via Gopher, que foi criado como uma alternativa ao Archie por Mark McCahill na Universidade de Minnesota em 1991.
.
Neste momento, no entanto não havia World Wide Web. A principal forma de compartilhar dados com pessoas na época era através do:File Transfer Protocol (FTP).
Se você tivesse um arquivo que você quisesse compartilhar você poderia configurar um servidor FTP. Se alguém estava interessado em recuperar os dados eles poderiam usar um cliente de FTP. Este processo funcionava eficazmente em grupos pequenos, mas os dados tornaram-se tão fragmentados que não era viavel.
O site de busca é mais uma expressão que foi criado na era da Internet e da computação e como tantas vezes é
composta de palavras que são de uso comum com seus significados originais. "Search" significa simplesmente "examinar em detalhes", geralmente com o objectivo de tentar encontrar alguém ou algo. Se você perder as chaves do carro Você ira procurar na sua casa de cima para baixo porque você sabe que elas estão em algum lugar da casa. Novamente, se a polícia suspeitar que alguém está a levar a algo como uma droga ilegal, eles podem muito bem "pesquisar" essa pessoa, o que significa que irá verificar os bolsos e todos os itens de vestuário. E depois há a outra metade da expressão: "motor". Isto significa que uma máquina que com a ajuda de algum tipo de energia ira permitir que algo se mova, como o motor do carro ", a máquina a vapor". Quando a primeira palavra que veio a ser usada ele teve a idéia de capacidade natural ou gênio. Então, quando você colocar as duas palavras juntas como "motores de busca" há uma oportunidade certa, quando você considera como esses dispositivos são cada vez mais inteligente. Mas agora a pergunta é:
Como funcionam os sites de busca na internet?
Motores e sites de busca usam aranhas ?
O que é um Bot?
O que é um Spider bot?
1. Todo site de busca tem um gigantesco banco de dados que serve de base para as pesquisas na rede. Isso é feito por programas chamados "robôs" ou "aranhas". Eles varrem a internet e gravam o texto de todos os sites que encontram, num ritmo de algumas centenas de páginas por segundo
2. O programa de busca guarda informações como a posição de cada palavra nos sites varridos e o tamanho em que ela aparece. Por exemplo: se você digitar "beatles" no campo de busca e essa palavra estiver no título de uma página, com letras grandes, esse site tende a aparecer bem ranqueado, ou seja, entre os primeiros resultados da pesquisa
3. Mas o fator que mais influi para o ranqueamento é outro: a quantidade de links que apontam para o site. O Google atribui mais valor aos links de páginas que, por sua vez, também são apontadas por muitas outras. Então vale mais um link que esteja indicado no site da Universidade de Harvard, por exemplo, do que num blog qualquer
4. Também conta se o link que leva à página der uma informação extra. Imagine que você tenha um site sobre os Beatles e alguém digite "letras dos beatles" no Google. Se outras páginas tiverem um link escrito "letras dos beatles" que leve ao seu site, ele ganha mais valor
Robôs de computador são simplesmente programas que automatizam tarefas repetitivas em velocidades impossíveis para o ser humano reproduzir. O termo bot na internet é geralmente usado para descrever qualquer coisa que faz interface com o usuário ou que coleta dados.
SItes de busca usam "aranhas", na web para obter informações. Eles são programas de software semelhante a navegadores regulares. Além de ler o conteúdo das páginas aranhas indexação links também em tempo recorde tudo isso graças a evolução historica dos sites de busca.
Citações sobre Link * pode ser usado como um proxy para a confiança editorial.
* Texto âncora de link pode ajudar a descrever o que uma página é sobre seu assunto.
* Link de dados para citação pode ser utilizado para ajudar a determinar o que as comunidades ou sobre um tópico de uma página ou im site existente
* Além disso as ligações são armazenadas nos motores de busca para ajudar a descobrir novos documentos para posterior rastreamento.
Outro exemplo poderia ser bot Chatterbots, que são recursos pesados sobre um tópico específico. Estes robôs tentão agir como um humano e se comunicar com seres humanos no referido tema.
Um search engine, site de busca, motor de busca, motor de pesquisa ou máquina de busca opera na seguinte ordem:
- Web crawling (percorrer por links)
- Indexação
- Busca
Os sistemas de busca trabalham armazenando informações sobre um grande número de páginas, as quais eles obtém da própria WWW (Internet). Estas páginas são recuperadas por um Web crawler (também conhecido como spider) — um Web browser automatizado que segue cada link que vê. As exclusões podem ser feitas pelo uso do robots.txt. O conteúdo de cada página então é analisado para determinar como deverá ser indexado (por exemplo, as palavras são extraídas de títulos, cabeçalhos ou campos especiais chamados meta tags). Os dados sobre as páginas são armazenados em um banco de dados indexado para uso nas pesquisas futuras. Alguns sistemas, como o do Google, armazenam todo ou parte da página de origem (referido como um cache) assim como informações sobre as páginas, no qual alguns armazenam cada palavra de cada página encontrada, como o AltaVista. Esta página em cache sempre guarda o próprio texto de busca pois, como ele mesmo foi indexado, pode ser útil quando o conteúdo da página atual foi atualizado e os termos de pesquisa não mais estão contidos nela. Este problema pode ser considerado uma forma moderada de linkrot (perda de links em documentos da Internet, ou seja, quando os sites deixaram de existir ou mudaram de endereço), e a maneira como o Google lida com isso aumenta a usabilidade ao satisfazer as expectativas dos usuários pelo fato de o termo de busca estarem na página retornada. Isto satisfaz o princípio de “menos surpresa”, pois o usuário normalmente espera que os termos de pesquisa estejam nas páginas retornadas. A relevância crescente das buscas torna muito útil estas páginas em cache, mesmo com o fato de que podem manter dados que não mais estão disponíveis em outro lugar.
Quando um usuário faz uma busca, tipicamente digitando palavras-chave, o sistema procura o índice e fornece uma lista das páginas que melhor combinam ao critério, normalmente com um breve resumo contendo o título do documento e, às vezes, partes do seu texto. A maior parte dos sistemas suportam o uso de termos booleanos AND, OR e NOT para melhor especificar a busca. E uma funcionalidade avançada é a busca aprocimada, que permite definir a distância entre as palavras-chave.
A utilidade de um sistema de busca depende da relevância do resultado que retorna. Enquanto pode haver milhões de páginas que incluam uma palavra ou frase em particular, alguns sites podem ser mais relevantes ou populares do que outros. A maioria dos sistemas de busca usam métodos para criar um ranking dos resultados para prover o "melhor" resultado primeiro. Como um sistema decide quais páginas são melhores combinações, e qual ordem os resultados aparecerão, varia muito de um sistema para outro. Os métodos também modificam-se ao longo do tempo, enquanto o uso da Internet muda e novas técnicas evoluem. A maior parte dos sistemas de busca são iniciativas comerciais suportadas por rendimentos de propaganda e, como resultado, alguns usam a prática controversa de permitir aos anunciantes pagar para ter sua listagem mais alta no ranking nos resultados da busca.
A vasta maioria dos serviços de pesquisa são rodados por empresas privadas usando algoritmos proprietários e bancos de dados fechados, sendo os mais populares o Bing, Google, Ask, AltaVista, Yahoo! Search. De qualquer forma, a tecnologia de código-aberto para sistemas de busca existe, tal como ht://Dig, Nutch, Egothor, OpenFTS, DataparkSearch e muitos outros.
Princípios do motor de busca comum
Para entender melhor sobre os sites de busca você prescisa estar ciente da arquitetura dos motores de busca. Todos eles contêm os seguintes componentes principais:
Spider - um navegador como o programa que baixa as páginas web.
Rastreador - um programa que segue automaticamente todos os links em cada página da web.Indexador - um programa que analisa as páginas web baixado pela aranha eo rastreador.
Banco de dados de armazenamento de páginas de download e processado.
Resultados do motor - certidões de resultados de pesquisa do banco de dados.
Servidor Web - um servidor que é responsável pela interação entre o usuário e outros componentes do motor de busca.
Implementações específicas de mecanismos de pesquisa podem ser diferentes. Por exemplo, o Aranha + rastreador + grupo componente do indexador pode ser implementado como um único programa que as páginas de downloads da Web, analisa-os e então usa os seus links para encontrar novos recursos. No entanto, os componentes listados são inerentes a todos os motores de busca SEO e os princípios são os mesmos.
Spider. Downloads Este programa procura páginas da web como um web browser. A diferença é que um navegador exibe as informações apresentadas em cada página (texto, gráficos, etc), enquanto uma aranha não tem qualquer componente visual e trabalha diretamente com o código HTML subjacente da página. Você já deve saber que existe uma opção em navegadores web padrão para exibição de código fonte HTML.
Rastreador. Este programa encontra todos os links em cada página. Sua tarefa é determinar onde a aranha deve ir ou avaliando os links ou de acordo com uma lista pré-definida de endereços. O rastreador segue estas ligações e tenta não encontrar os documentos que já se sabe que o motor de busca.
Indexador. Esse componente analisa cada página e analisa os diferentes elementos, como texto, cabeçalhos, características estruturais ou estilísticas, tags HTML especiais, etc
Banco de Dados. Esta é a área de armazenamento para os dados que o motor de busca de downloads analisa. Às vezes ele é chamado de índice do motor de busca.
Mecanismo de Resultados. O motor de resultados classifica as páginas. Ela determina quais as páginas que melhor corresponder à consulta de um usuário e em que ordem as páginas devem ser listados. Isso é feito de acordo com os algoritmos de classificação do mecanismo de busca. Daqui resulta que page rank é uma propriedade valiosa e interessante e qualquer especialista de SEO é o mais interessado em que quando se tenta melhorar os seus resultados de busca do site. Neste artigo, vamos discutir os fatores que seo page rank influência em alguns detalhes.
Servidor web. O motor de busca do servidor web normalmente contém uma página HTML com um campo de entrada onde o usuário pode especificar a busca ele ou ela está interessado em O servidor web também é responsável por exibir resultados de pesquisa para o usuário na
forma de uma página HTML.
Partes de um motor e site de pesquisa

Os motores de busca ou sites de busca consistem em 3 partes principais. Motor de busca aranhas que seguem os links na web para páginas solicitadas que não estão ainda indexadas ou foram atualizadas desde a última indexação. Estas páginas são rastreadas e são adicionados ao índice do Search Engine (também conhecido como o catálogo ou sites de busca).
Quando você pesquisa usando um site de busca principal ou qualquer site de busca que quer dizer a mesma coisa como por exemplo o google você não está realmente procurando na internet, mas estão à procura de um índice um pouco ultrapassado de conteúdo, que representa aproximadamente o conteúdo da web. A terceira parte de um motor de busca é a interface de busca e o software de relevância. Para cada pesquisa os motores de busca costuma fazer consulta na maioria ou a todos os seguintes parametros

* Aceite do usuário a consulta digitada, verificando para coincidir com qualquer sintaxe avançada e verificação para ver se a consulta é incorreta para recomendar
variações ortográficas mais popular ou corretas.
* Verifica busca de notícia, se a consulta é relevante para outras bases de dados de busca vertical (como a pesquisa ou produto) e colocar links relevantes para alguns itens do tipo de consulta de pesquisa e perto os resultados de pesquisa regular.
* Reunir uma lista de páginas relevantes para os resultados da busca orgânica. Estes resultados são classificados com base no conteúdo da página, os dados de uso e dados de citação link.
* Pedir uma lista de anúncios relevantes para colocar perto os resultados da pesquisa.
Usuarios de sites de busca geralmente tendem a clicar principalmente na parte superior de alguns resultados de pesquisa, como observado no presente artigo e quanto melhor um site indexado melhor o trafego gerado pelos Searchers,buscadores.
|

Bancos de dados de sites de busca são selecionados e construídos por programas robô de computador chamados aranhas. Estes "rastreadores" da web, Localizam páginas para inclusão seguindo os links nas páginas que já têm em seu banco de dados.Não é possível usar a imaginação ou inserir termos nas caixas de pesquisa que se encontram na web.
Depois da aranha encontrar as páginas elas vão para outro programa de computador para a "indexação". Este programa identifica o texto, links e outros conteúdos na página e armazena em arquivos do site de busca no banco de dados para que o banco de dados possa ser pesquisado por palavra-chave e qualquer abordagem mais avançada são oferecidas e a página será encontrada se sua pesquisa corresponde ao seu conteúdo.
Muitas páginas da web são excluídas da maioria dos motores de busca pela política da empresa. O conteúdo da maioria dos banco de dados pesquisáveis montados na web, como catálogos de biblioteca e bancos de dados do artigo, está excluído porque aranhas de site de pesquisa não podem acessá-los. Todo esse material é referido como o "Invisible Web"-- Ou tudo aquilo que você não vê nos resultados dos sites de busca.
Os sites de busca funcionam do mesmo geito: montam um banco de dados com o texto de milhões de páginas e mostram aqueles que têm a ver com a palavra que você digitou na tela de procura. A diferença está nos detalhes. Tipo: que página deve aparecer primeiro? Se você digita algo como "São Paulo", o site de buscas não sabe se você está atrás de informações sobre a maior cidade do país ou sobre o santo. Mas ele tem que dar um jeito de "saber o que você está pensando". Cada site usa fórmulas específicas para ordenar os resultados de uma pesquisa. O jeito

mais comum, hoje, é colocar no topo da lista as páginas que recebem mais links de outros sites.
Mas o endereço de busca mais popular na rede, o Google (www.google.com.br), inventou um jeito de ir mais longe: o link de uma página respeitada vale mais que um link qualquer. Os gênios por trás da tecnologia de busca do site são dois engenheiros da computação: Sergey Brin e Larry Page, que apresentaram o Google num artigo de divulgação científica de 1998. Na época, o site era só um projeto de faculdade, para a Universidade de Stanford, na Califórnia. Hoje, vale pelo menos 20 bilhões de dólares e é a empressa que mais cresceu no mundo.
* Como o Google coleta e ordena seus resultados? Engenheiro do Google Matt Cutts discute brevemente como o Google funciona.
* Engenheiro do Google Jeff Dean da palestras a uma classe da Universidade de Washington sobre a forma como uma consulta de pesquisa no Google funciona
* O Chicago Tribune publicou um artigo especial intitulado Gunning para o Google, incluindo cerca de uma dúzia de entrevistas em áudio, 3 colunas, e este gráfico sobre como o Google funciona.
* Como funcionam os motores de busca da Internet.
Custos de armazenamento e tempo de crawling
Os custos de armazenamento não são o limitador na implementação de um sistema de site de busca. Armazenar simplesmente 10 bilhões de páginas de 10 kbytes cada (comprimidas) requer 100TB e outros aproximados 100TB para índices, dando um custo de hardware total em menos de $200k: 400 drives de disco de 500GB em 100 PCs baratos.
De qualquer forma, um sistema público de busca consideravelmente requer mais recursos para calcular os resultados e prover alta disponibilidade. E os custos de operar uma grande server farm não são simples. Passar por 10B páginas com 100 máquinas percorrendo links a 100 páginas/segundo levaria 1M segundos, ou 11.6 dias em uma conexão de Internet de alta capacidade. A maior parte dos sistemas percorre uma pequena fatia da Web (10-20% das páginas) perto desta freqüência ou melhor, mas também percorre sites dinâmicos (por exemplo, sites de notícias e blogs).
Tipos de pesquisas na Internet:
Andrei Broder autor de Uma Taxonomia de Pesquisa na web [PDF], que observa que a maioria das pesquisas cai nas 3 categorias seguintes:
* Informativa - buscando informações estáticas sobre um tópico
* Transacional - fazer compras , baixando ou de outra forma interagir com o resultado
* Navegavel - enviar para uma URL específica
Melhorar suas Buscas:
* Páginas de pesquisa avançadas que ajudam os pesquisadores a refinar suas consultas para solicitar arquivos que são mais novos ou mais velhos, locais ou na natureza, em domínios específicos, publicado em formatos específicos, ou outras formas de pesquisa de refino, por exemplo, [Historia dos sites de busca 2009 OR 2010]
* Bancos de dados de pesquisa Vertical que podem ajudar a estruturar o índice de informação ou limitar a pesquisa a um índice mais confiável ou melhor coleção estruturada de fontes, documentos e informações uteis.
Google Nancy Blachman este guia oferece aos pesquisadores dicas de pesquisa gratuita do Google
Há também muitos outros populares e pequenos serviços de busca diferenciados. Por exemplo, Del.icio.us permite pesquisar URLs que os usuários tenham marcado, e Technorati permite pesquisar blogs.
World Wide Web Wanderer:
Em junho de 1993 Matthew Gray apresenta o World Wide Web Wanderer. Ele inicialmente queria medir o crescimento da web e criou este robô para contar servidores web ativo. Ele logo atualizava o bot para capturar URL verdadeiras. Seu banco de dados tornou-se conhecido como a Wandex.
Wanderer foi um grande problema porque era uma solução que causou muito problema no sistema (lag), acessando a mesma página, centenas de vezes por dia. Não demorou muito para ele,corrigir esse software, mas as pessoas começaram a questionar o valor desses bots.
Aliweb:
Em outubro de 1993 Martijn Koster criou o Archie-Like Indexing da Web, ou Aliweb em resposta à Wanderer. Aliweb crawled não precisava de bot para coletar dados e não estava usando largura de banda excessiva. A desvantagem de Aliweb é que muitas pessoas não sabem como submeter seu site.
Robots Exclusion Standard:
Martijn Kojer também hospeda a página web robots, que criou normas para os motores de busca como o conteúdo de índice deve agir ou não. Isso permite que os webmasters posão bloquear bots do seu site em um nível local inteiro ou página por página.
Por padrão, se a informação está em um servidor web público, e as pessoas apontam para ele os motores de busca irião,a partir dele. Uma das principais desvantagens apontadas aos robots é o facto de efectuarem uma indexação indescrimidada dos recursos de informação. O Aliweb pretende disponibilizar uma solução para a indexação dos recursos HTTP, alternativa à oferecida pelos robots, e que ultrapassa de alguma forma esta insuficiência.
A arquitectura proposta por este serviço é muito parecida com a arquitectura do Archie. O Aliweb recolhe os ficheiros que contêm as listas dos recursos que se pretendem indexar, ficheiros esse que são mantidos nos servidores HTTP e a partir daí constrói uma base de dados global de índices.

Em 2005, o Google liderou uma batalha contra o spam de comentários, criando um atributo "nofollow" que podem ser aplicadas no link individual. Após isto o Google mudou rapidamente o alcance da finalidade do link "nofollow" para reclamar qualquer link que foi vendido ou não sob o controle editorial.
Sites de busca antigos:
Até dezembro de 1993, forão três bots desenvolvidos e alimentados com motores de busca que surgiram na web: jumpstation, a World Wide Web Worm, e o repositório-Based Software Engineering (RBSE) aranha. Jumpstation recolhia informações sobre o título e o cabeçalho das páginas da Web e recuperava usando uma pesquisa simples e linear. À medida que a web cresceu, jumpstation foi reduzindo seu trabalho até parar. O problema com jumpstation e da World Wide Web Worm é que os resultados listados erão na ordem em que os encontrou, e desde que haja discriminação. A aranha RSBE colocava em prática um sistema de classificação,mas se você não souber o nome exato do que você estava procurando era extremamente difícil na verdade quaze impossivel de encontrá-lo.
Sites de buscas novos:
Uma recente melhoria na tecnologia de busca é a adição de geocodificação e geoparsing para o processamento dos documentos ingeridos. O geoparsing tenta combinar qualquer referência encontrada a lugares para um quadro geoespacial de referência, como um endereço de rua, localizações de dicionário de termos geográficos, ou a uma área (como um limite poligonal para uma municipalidade). Através deste processo de geoparsing, as latitudes e longitudes são atribuídas aos lugares encontrados e são indexadas para uma busca espacial posterior. Isto pode melhorar muito o processo de busca pois permite ao usuário procurar documentos para uma dada extensão do mapa, ou ao contrário, indicar a localização de documentos combinando com uma dada palavra-chave para analisar incidência e agrupamento, ou qualquer combinação dos dois.

Uma empresa que desenvolveu este tipo de tecnologia é a MetaCarta, que disponibiliza seu produto como um XML Web Service para permitir maior integração às aplicações existentes.A MetaCarta também provê uma extensão para o programa GIS como a ArcGIS (ESRI) para permitir aos analistas fazerem buscas interativamente e obter documentos em um contexto avançado geoespacial e analítico. Veja também o MetaCarta AnyPaget.
O Google é atualmente o mecanismo de busca mais utilizado. Ele tem um dos maiores bancos de dados de páginas da Web, incluindo muitos outros tipos de documentos web (blog mapas, páginas wiki, segmentos de discussão do grupo e formatos de documento (por exemplo, PDFs, Word ou Excel documentos, PowerPoints).
Mesmo assim o Google sozinho nem sempre é suficiente. Nem tudo na Web é totalmente pesquisável no Google.Estudos mostrão que mais de 80 % das páginas no banco de dados de um motor de busca importante existe apenas no banco de dados. Por esse motivo, obter uma "segunda opinião" pode valer seu tempo. Para este efeito, recomendamos Yahoo! Search ou Exalead. Não recomendamos utilizar motores de meta-search como sua ferramenta de pesquisa principal.
Tabela de algumas técnicas comuns que funcionarão em qualquer site de busca com recursos. No entanto, nesta indústria muito competitiva, sites de busca também oferecem recursos exclusivos. Em caso de dúvida, procure "help", "FAQ", ou "sobre" links nos sites de busca.
| Saites de busca |
Google
www.google.com |
Yahoo! Search
search.yahoo.com |
Exalead
www.exalead.com/search/ |
| Links de ajuda |
Google help |
Yahoo! help |
Exalead help and FAQ |
|
Tamanho, tipo
|
IMENSO. Tamanho não divulgado em qualquer forma que permite a comparação. Provavelmente o maior.
|
ENORME. Alega ter um total de mais de 20 bilhões "objetos da web". |
GRANDES. Alega ter mais 8 bilhões de páginas pesquisáveis. |
Recursos notáveis |
PageRank™ sistema que inclui centenas de fatores, enfatizando as páginas mais fortemente ligadas a partir de outras páginas.
Muitos outros bancos de dados incluindo pesquisa de livros, acadêmico (diário de artigos), Blog Search, patentes, imagens, etc.. |
Atalhos de dar acesso rápido ao dicionário, sinónimos, patentes, tráfego, das existências, enciclopédia e muito mais. |
Truncamento permite pesquisar pelas primeiras letras de uma palavra.
Pesquisa de proximidade permite localizar termos NEAR uns aos outros ou seguinte para uns aos outros.
Visualizações de miniaturas de página.
Extensas opções de refinação e limitar sua pesquisa. |
| Frase de pesquisa |
Coloque a frase "aspas".
|
Coloque a frase entre "aspas duplas". |
Coloque a frase "aspas". |
Lógica booleana |
Parcial. E assumidas entre palavras.
Capitalizar ou.
() aceite mas não obrigatório.
Na pesquisa avançada, Boolean parcial disponível nas caixas. |
Aceita AND, OR, NOT ou AND NOT. Deve estar em letras maiúsculas.
() aceite mas não obrigatório. |
Parcial. E assumidas entre palavras.
Capitalizar ou.
aceite ().
Veja sintaxe de pesquisa da Web para mais opções |
| + Requer o /exclui |
-exclui + recupera "stop palavras" (por exemplo, + in) |
-exclui + permitirá que você pesquise palavras comuns: "+ na verdade" |
-exclui + recupera stop palavras (por exemplo, + em).
- excludes
|
| Sub-Searching |
A caixa de pesquisa no topo da página de resultados mostra pesquisa atual. Modificar isso (por exemplo, adicionar mais termos no fim.) |
A caixa de pesquisa no topo da página de resultados mostra pesquisa atual. Modificar isso (por exemplo, adicionar mais termos no fim.) |
A caixa de pesquisa no topo da página de resultados mostra a pesquisa atual. Modificar isso (por exemplo, adicionar mais termos no fim.) |
| Resultados de classificação |
Com base na página e popularidade medida em links para ele de outras páginas e sites: classificação alta se um numero de outras páginas vincular a ele.
Fuzzy.
Correspondência e classificação com base na versão "cache" de páginas que não pode ser a versão mais recente. |
Fuzzy AND automática. |
Ranking de popularidade enfatiza páginas mais fortemente vinculadas de outras páginas. |
| Campo limitar a busca |
ink:
site:
intitle:
inurl:
oferece U.S.Gov't buscas e outras pesquisas buscas especiais . buscas de Patentes.
|
link:
site:
intitle:
inurl:
url:
hostname:
(Explicação destas distinções)
|
intitle:
inurl:
site:
after:[time period]
before:[time period]
(Para mais detalhes click em "Advanced search") |
| Truncamento, raiz |
Sem truncamento. Deriva algumas palavras. Pesquisar terminações variantes e sinónimos separadamente, separando com ou (em letras maiúsculas): reparo de modulo bmw OR |
Pesquisa com ou como no Google. |
Use *
exemplo: mensagem* |
| Língua |
Sim. Os principais Idiomas e línguas pesquisa avançada. |
Sim. Os principais Idiomas e línguas.. |
Língua extensa e opções geográficas. Use "Pesquisa avançada". |
| Tradução |
Sim, no link "Traduzir esta página" após algumas páginas. Para o inglês e principais línguas europeias e chinês, japonês, coreano.Tem seu próprio software de tradução com os comentários do usuário.
Ou direto Google tradutor |
Disponivel em um serviço separo no site de traduções do Yahoo.com o Babelfish
|
Notáveis sites de busca
1994: Yahoo! criado por estudantes da Universidade de Stanford Jerry Wang e David Filo em um trailer do campus. O Yahoo foi inicialmente uma lista de favoritos da Internet e diretório de sites interessantes.
1996: Sergey Brin e Larry Page, dois estudantes da Universidade de Stanford testou o BackRub, um novo motor de busca que classifica sites com base em relevância da ligação de entrada e de popularidade. Backrub acabaria por se tornar o Google.BackRub era escrito em Java e Python e funciona!
- Larry e Sergey, agora estudantes com graduação em ciência da computação em Stanford começarão a trabalhar em um mecanismo de pesquisa chamado BackRub.
- BackRub operava em servidores de Stanford por mais de um ano - eventualmente ocupou muita largura de banda para se adequar a universidade.
1998: Goto.com funcionava com Links Patrocinados e busca paga. Anunciantes colocavão seu anuncio em Goto.com a classificação dos resultados de pesquisa orgânicas que eram movidas por Inktomi. Goto.com é basicamente adquirida pela Yahoo.
2000: Os parceiros do Google e Yahoo com o poder do Google permite que seus resultados orgânicos em vez de Inktomi. Antemão o Google foi um motor de busca pouco conhecido. O resultado final, o Yahoo apresenta seu maior concorrente para o mundo e Google torna-se um nome familiar.
2003: Google lança AdSense depois de adquirir Blogger.com. AdSense serve para anúncios contextuais do Google AdWords em sites de editor. A mistura de AdSense e Blogger leva a um aumento na publicação na Internet monetizadas simples e uma revolução dos blogs.
2006: Google adquire gerado pelo usuário da rede de compartilhamento de vídeos YouTube, que finalmente passa a ser propriedade de busca mais usado no 2 do mundo. O Google está trabalhando ainda devidamente monetizar o YouTube.
2009: Em uma tentativa de desafiar o Google que domina 70% do mercado de sites de busca, Yahoo e Microsoft se unem para tentar bater o google..
Existem variados tipos de buscadores e sites de busca:
- Buscadores globais são buscadores que pesquisam os documentos na rede, e a apresentação do resultado é aleatória, dependendo do ranking de acessos aos sites e mais alguns outros farores dependendo do site de busca utilizado, as buscas podem ser sobre qualquer tema. Google, Yahoo, MSN são os buscadores globais mais acessados.
- Buscadores verticais são buscadores que realizam pesquisas "especializadas" em bases de dados próprias de acordo com suas propensões. Geralmente, a inclusão em um buscador vertical está relacionada ao pagamento de uma mensalidade ou de um valor por clique. BizRate, AchaNoticias, Oodle, Catho, SAPO, BuscaPé e Become.com são alguns exemplos de buscadores verticais.
- Guias locais são buscadores exclusivamente locais ou regionais. As informações se referem a endereços de empresas ou prestadores de serviços. O resultado é priorizados pelo destaque de quem contrata o serviço. ILocal, GuiaMais, AcheCerto, EuAcheiFácil entre outras. Geralmente são cadastros e publicações pagas. É indicado para profissionais e empresas que desejam oferecer seus produtos ou serviços em uma região, Estado ou Cidade.
- Guias de busca local ou buscador local são buscadores de abrangência nacional que lista as empresas e prestadores de serviços próximas ao endereço do internauta a partir de um texto digitado. A proximidade é avaliada normalmente pelo cep, Donavera.com, ou por coordenadas de GPs. Os cadastros Básicos são gratuitos para que as micros empresas ou profissionais liberais possam estar presente na WEB sem que invistam em um sites próprio. É indicado para profissionais e empresas que desejam oferecer seus produtos ou serviços em uma Localidade, rua, bairro, cidade ou Estado e possibilitando ainda a forma mais rápida de atualização dos registros de contatos por seus clientes ou fornecedores.
- Diretórios de websites são índices de sites, usualmente organizados por categorias e sub-categorias. Tem como finalidade principal permitir ao usuário encontrar rápidamente sites que desejar, buscando por categorias, e não por palavras-chave. Os diretórios de sites geralmente possuem uma busca interna, para que usuários possam encontrar sites dentro de seu próprio índice. Diretórios podem ser a nivel regional, nacional ou global, e até mesmo especializados em determinado assunto. Open Directory Project é exemplo de diretórios de sites.
Pesquisando Documentos na Internet

Podemos considerar dois aspectos na utilização da Internet como ferramenta associada à Pesquisa:
A busca de documentos (páginas, figuras, textos e animações), ou seja, como encontrar os endereços nessa grande Rede; a utilização dos recursos institucionais disponíveis "on line" para revisão bibliográfica, ou seja, quais os endereços e principais fontes para a pesquisa bibliográfica.
Buscando documentos na Internet
Aproximadamente 90% das Universidades no mundo inteiro estão conectadas à Internet e disponibilizam muito material através de suas páginas institucionais, o mesmo ocorrendo com Institutos de Pesquisa, Organizações Não-Governamentais etc.
Estamos vivendo uma grande modificação tanto no segmento de serviços quanto na propaganda muitos Analistas afirmam que estamos vivendo a denominada "febre do .com", ou seja, há uma explosão de informações na WWW, sendo esta principalmente de caráter comercial.
O boom comercial somado a disponibilização do acesso gratuito e a falta de investimentos na ampliação da capacidade da Rede no Brasil estão diretamente relacionado ao crescente congestionamento (causando essa lentidão crescente na rede).
Portanto, nós pesquisadores, para aproveitarmos esses recursos de maneira eficiente devemos utilizar ferramentas e métodos especiais de busca pois a questão principal é " Como obter os endereços de páginas que contenham o assunto (referenciado, atualizado) que procuramos ?"
Para localizar tais informações sobre temas específicos, ou para obter os endereços de universidades, bibliotecas, enciclopédias, centros de pesquisa devemos usar os serviços dos sites de busca.
BUSCA SIMPLES
Inicialmente foram sendo disponibilizados endereços de páginas com um sistema de busca em seus bancos de dados contendo informações sobre endereços e conteúdos de páginas. Este tipo de serviço são disponibilizados nos endereços ou páginas de Busca, como por exemplo os nacionais e internacionais:
(https://www.igpromo.com.br/sites-de-busca-portugues.asp)
Google (https://www.google.com.br)
AltaVista (https://br.altavista.com)
Cadê (https://br.cade.yahoo.com)
RadarUOL (https://www.radaruol.com.br)
Lycos (https://www.lycos.com)
HotBot (https://www.hotbot.com)
Excite (https://www.excite.com)
Devemos gravar os endereços de busca nos favoritos e ao pesquisarmos um tema devemos utilizar os vários serviços de busca. Essas buscas devem ser estendidas a todos os recursos da Internet inclusive Newsgroups e Web, e que podem fornecer e-mails de pesquisadores da área procurada. Esta busca na Web pode nos levar também a sites de Gopher e Telnet, portanto devemos salvá-los também.
Como indicação considero o Altavista como um dos melhores sites de busca, porém hoje temos o Google como uma importante ferramenta de Busca, principalmente entre documentos em Universidades.
O Altavista, além de ter um dos maiores bancos de dados, possui uma vasta estrutura de ajuda a entender as formas de busca disponíveis com grande quantidade de informações importantes. Entre os principais recursos temos:
- A página principal com as opções de busca: (1) simples; (2) avançada; (3) de imagens; (4) de arquivos de som; (5) de vídeos e; (6) através de diretórios da Web (por assuntos).
 A página com o sistema de ajuda https://br.altavista.com/help, onde você poderá verificar os dados relacionados a este incrível site de busca, aprender as diferenças entre os diversos sistemas busca existentes no altavista e etc..
A página com o sistema de ajuda https://br.altavista.com/help, onde você poderá verificar os dados relacionados a este incrível site de busca, aprender as diferenças entre os diversos sistemas busca existentes no altavista e etc..
- Consulte as páginas de ajuda sobre como buscar documentos no modo básico é https://br.altavista.com/help/search/default e no modo avançado de busca https://br.altavista.com/help/search/help_adv, pois você aprenderá uma série de "macetes" bastante úteis.
- Abaixo está a figura com o modo de pesquisa avançado:

- Você poderá aprender a utilizar expressões Booleanas, termo derivado da álgebra de Boole (matemático e lógico nascido na Inglaterra no sec. XIX), que envolve a aplicação das operações da teoria dos conjuntos e da lógica a dois ou mais conjuntos e proposições. Você pode usar esses termos booleanos tanto para pesquisas no modo básico quanto no avançado. Para pesquisas avançadas, digite-os na caixa booleana de forma livre. Veja a tabela abaixo com os principais termos especiais de pesquisa:
AND Para pesquisas avançadas, digite-os na caixa booleana de forma livre. Amendoim AND manteiga encontra documentos tanto com a palavra amendoim quanto com a palavra manteiga.
OR Encontra documentos contendo pelo menos uma das palavras ou frases especificadas. Amendoim OR manteiga encontra os documentos contendo ou amendoim ou manteiga. Os documentos encontrados podem conter ambos os termos, mas não necessariamente.
AND NOT Exclui documentos contendo a palavra ou frase especificada. Amendoim AND NOT manteiga encontra documentos com amendoim mas não contendo manteiga. NOT precisa ser usado com um outro operador, como E. O AltaVista não aceita 'amendoim NOT manteiga'; no lugar, especifique amendoim AND NOT manteiga..
NEAR Localize documentos contendo tanto as palavras quanto as frases especificadas com 10 palavras entre uma e outra. Amendoim NEAR de manteiga encontraria documentos com amendoim manteiga, mas provavelmente nenhum outro tipo de manteiga.
* O asterisco é um curinga; quaisquer letras podem tomar o lugar do asterisco. Bass* Bass encontraria os documentos com bass, basset e bassinet.
Você precisa digitar pelo menos três letras antes de Você também pode colocar o no meio de uma palavra. Isso é útil quando você não tem certeza sobre soletrar.Cor encontraria documentos que contêm color e colour.
( ) Use parênteses para agrupar frases Booleanas complexas. Por exemplo, (amendoim AND manteiga) AND (gelatina OR geléia) localiza documentos com as palavras 'amendoim manteiga e gelatina' ou 'amendoim manteiga e geléia' ou ambos.
anchor:text Localiza páginas que contêm a palavra ou frase especificada no texto de um hiperlink. anchor:emprego +programação encontraria páginas com emprego em um link e com a palavra programação no conteúdo da página.
Não coloque um espaço antes ou depois de dois pontos. Você precisa repetir a palavra-chave para pesquisar mais de uma palavra ou frase; por exemplo, anchor:emprego OR âncora:carreira para localizar páginas com âncoras contendo ou a palavra emprego ou a palavra carreira.
applet:class Localiza páginas que contêm um applet Java específico. Use para localizar páginas utilizando applets chamados morph.
object:class Localiza páginas que contêm um objeto específico criado por outro programa por exemplo, um objeto que pisca).
Use object:dinheiro para localizar páginas utilizando objetos chamados dinheiro.
domain:domainname Localiza páginas dentro do domínio específico. Use domain:uk para localizar páginas do Reino Unido, ou use domain:com para localizar páginas de sites comerciais.
host:hostname Localiza páginas em um computador específico. A pesquisa host:www.shopping.com localizaria páginas no computador do Shopping.com e host:dilbert.unitedmedia.com localizaria páginas no computador chamado dilbert na unitedmedia.com.
image:filename Localiza páginas com imagens tendo um nome de arquivo específico. Use image:scour para localizar páginas com imagens chamadas scour.
like:URLtext Localiza páginas similares ou relacionadas ao URL especificado. Por exemplo, like:www.abebooks.com localiza sites da Web que vendem livros usados e raros, similar ao www.abebooks site. like:sfpl.lib.ca.us/ localiza sites de bibliotecas universitárias e públicas. like:https://www.indiaxs.com/ localiza sites sobre cultura no subcontinente Indiano.
link:URLtext Localiza páginas com um link para uma página com um texto do URL especificado. Use link:www.myway.com para localizar todas as páginas que fazem link com myway.com.
text:text Localiza páginas que contêm o texto especificado em qualquer parte da página, com exceção de uma tag de imagem, link ou URL. A pesquisa text:graduation localizaria todas as páginas com o termo graduação nelas.
title:text Localiza páginas que contêm a palavra ou frase especificadas no título da página (que aparece na barra do título da maioria dos navegadores). A pesquisa title:crepúsculo localizaria páginas com crepúsculo no título.
url:text Localiza páginas com uma palavra ou frase específicas no URL. Use url:jardim para localizar todas as páginas em todos os servidores que têm a palavra jardim em algum lugar no nome do host, na via ou no nome do arquivo.
- A página com os diretórios de busca também são muito interessantes https://br.altavista.com/dir/default , por exemplo faça uma busca sobre uma área das ciências. Você pode verificar na figura abaixo o Diretório principal, um campo de inserção de palavra-chave e os tópicos.

- Por exemplo, vamos realizar a busca de documentos em Inglês no período de 01/01/2000 a 29/05/2010 que contenham as palavras Human, Genetics e Behavior:. Esta busca obteve 33.015 resultados com páginas que contêm as três palavras ( uma dica: para não ter que ir clicando em um resultado e depois voltar para a página de busca, escolher outra visitar e voltar, clique com o outro botão do mouse sobre o link desejado e opte por abrir link em uma nova janela, com isso você pode abrir vários resultados ao mesmo tempo. Repare também que há um link para tradução do documento, este recurso utiliza o sistema Systran Babel Fish Translation. https://babelfish.altavista.com

- Veja que também é possível recortar e colar um texto dentro da área de tradução, escolher os idiomas e traduzir. Na figura abaixo está o quadro de Tradução.

Um bom exemplo de site de busca personalizado é o pesquisa nome de pessoas



 https://sites.google.com/site/pesquisanomedepessoas/ ele usa a engine do google para suas pesquisas mas com um diferencial ele esta configurado para utilizar expressões Booleanas para pesquisa que envolve a aplicação das operações da teoria dos conjuntos e da lógica a dois ou mais conjuntos e proposições. Você pode usar esses termos booleanos tanto para pesquisas no modo pesquisar nomes de pessoas ou na web. Simplificando quando você quizer pesquisar o nome de uma pessoa na Internet o site pesquisa nomes de pessoas já faz isso automatico procurando pelo nome em varias redes sociais, foruns e Internet. Para utilizar basta digitar nome e sobre nome com espaço e com toda a certeza se a pessoa procurada tiver utilizado a internet um dia o pesquisa nome de pessoas achara em questão de segundos. Pesquisa Nomes
https://sites.google.com/site/pesquisanomedepessoas/ ele usa a engine do google para suas pesquisas mas com um diferencial ele esta configurado para utilizar expressões Booleanas para pesquisa que envolve a aplicação das operações da teoria dos conjuntos e da lógica a dois ou mais conjuntos e proposições. Você pode usar esses termos booleanos tanto para pesquisas no modo pesquisar nomes de pessoas ou na web. Simplificando quando você quizer pesquisar o nome de uma pessoa na Internet o site pesquisa nomes de pessoas já faz isso automatico procurando pelo nome em varias redes sociais, foruns e Internet. Para utilizar basta digitar nome e sobre nome com espaço e com toda a certeza se a pessoa procurada tiver utilizado a internet um dia o pesquisa nome de pessoas achara em questão de segundos. Pesquisa Nomes
Na figura abaixo está a página principal do site de busca Cadê, que também apresenta uma boa estrutura não deixe de conhecer e se não aceitou as sugestões anteriores de leitura do help do Altavista não deixe de ler o do Cadê (https://www.cade.com.br/info.htm)

Dados obtidos na página (https://home.inter.net/takakuwa/search/searc2.html) indicam cerca de 3.105 sistemas de busca em 6 regiões do planeta em 211 países. Os apresentados acima podem ser considerados os principais, porém a melhor forma de realizar pesquisas na Internet é através de site de meta busca, ou seja, um sistema que procura suas palavras chaves em vários sistemas de busca ao mesmo tempo. Na página https://www.amdahl.com/internet/meta-index.html podemos verificar lista de sites de Busca
Entre os principais vamos destacar o metacrawler (https://www.metacrawler.com), o metafetcher (https://www.metafetcher.com); o all in one search page que fazia a busca em mais de 500 sistemas de busca fechou recentemente, o https://www.allonesearch.com. Com nome parecido há também o sistema no Reino Unido denominado https://www.allsearchengines.co.uk. No Brasil o melhor sistema de metabusca é o Sistema Miner (https://miner.bol.com.br/uol.html). Faça algumas pesquisas utilizando esse site.
O sistema miner Sistema Miner (https://miner.bol.com.br/uol.html) tinha um portal de acesso a vários tipos de metabusca que passaram a integrar a metabusca UOL - https://busca.uol.com.br/miner.jhtm
Na página dos resultados da busca são apresentados o quantitativo de respostas de cada sistema verificado e abaixo a lista dos resultados dispostos em grupos de 10. No final da página tem um índice de páginas de resultados. Quando este sistema foi lançado junto a Universidade Federal de Minas Gerais era fabuloso, pois apresentava todos os resultados da busca em uma única página, sem propagandas, sem demora. Infelizmente para nós Usuários, o criador do sistema negociou com a Universo On Line e hoje este sistema encontra-se ligado ao Brasil On Line (Grupo Abril) e na minha opinião deixou de ser eficiente, apresenta muita sobreposição de sites, além de ser demorado (devido as propagandas) Com toda a redução do sistema Miner passo a não recomendar esta ferramenta de busca.
Fontwapedia





























